
Users of large language models (LLMs) need to be confident in the safety, security, performance, trustworthiness and usefulness of the insights. In addition, it is often challenging to uncover hidden issues in agentic workflows. To address these concerns, IT, data engineering teams and developers can turn to LLM observability to diagnose and address issues concerning quality, safety, correctness and performance.
Let’s discuss the differences between LLM observability and LLM monitoring and their importance in the AI industry. Then we’ll explore how LLM observability and monitoring work, while highlighting key concepts. Finally, we’ll look at the benefits and challenges in LLM observability and monitoring.
The Differences Between LLM Observability and Monitoring
LLM observability gives teams full visibility into all the layers of an LLM system, including the application layer, response layer and prompt layer. Meanwhile, LLM monitoring is the process of evaluating whether LLM models meet the standards of fairness, relevance, factual accuracy and response time.
LLMs are prone to bias, toxicity and hallucinations. Observability is the systematic monitoring, evaluation and tracking of these problems in both the development and live usage stages.
LLM observability gives teams full visibility into all the layers of an LLM system, including the application layer, response layer and prompt layer.
Monitoring focuses instead on tracking the behavior and performance of LLMs while measuring specific metrics such as resource usage, latency and error rates. You can use monitoring to assess the precision, drift and accuracy of the model.
Observability provides insights into the operational aspects of LLMs, and can provide a deeper understanding of why problems are happening. By concentrating on debugging, performance optimization, root cause analysis and anomaly detection, observability provides insights into workflows and interactions between system layers.
The Importance Observability in AI and the Tech Landscape
Monitoring and observability provide structured ways to track and analyze LLM performance, simplify fine-tuning and deployment, and ensure the continuous improvement of these models.
In the larger technology landscape, monitoring and observability apply to applications, infrastructure and networks, helping you gain insights into the health, behavior and performance of your IT operations. When AI and observability work together, they provide many opportunities to developers, including automated performance monitoring. Observability helps you deliver reliable, performant and secure LLM-powered applications.
How LLM Observability and Monitoring Work
How LLM Observability Works
There are various pillars of LLM observability, including model evaluation, model fine-tuning, prompt engineering, tracing, search and retrieval.
- Evaluating LLMs: This process measures how well the model’s responses address the prompt. Evaluation is done by gathering user feedback or using another LLM to assess responses. The goal is to identify patterns in problematic responses and improve the LLM’s performance. Typically, LLM performance benchmarks are evaluated against public and internal benchmarks.
- Traces and spans: Help uncover hidden issues in agentic workflows, which break down complex tasks into iterative and multistep processes, helping LLMs execute complex tasks with more accuracy. In agentic workflows, isolating specific calls or steps within a process (spans) is critical. By evaluating different spans within a trace, developers can identify where issues arise and optimize performance accordingly.
- Prompt engineering: Involves iterating and refining prompts to improve LLM performance, and includes providing context in prompts to help LMMs deliver more relevant responses.
- Search and retrieval: Feeding more relevant information to the LLM greatly enhances performance. Search and retrieval involve embedding data efficiently, possibly in multiple stages, to improve the relevance of the information the LLM uses to generate responses.
- Fine-tuning the model: This pillar involves training the model further to align with specific use cases. Fine-tuning is expensive and complex but can offer significant improvements in performance when done correctly by maintaining instrumented training pipelines that can gauge before/after key performance indicators of the model.
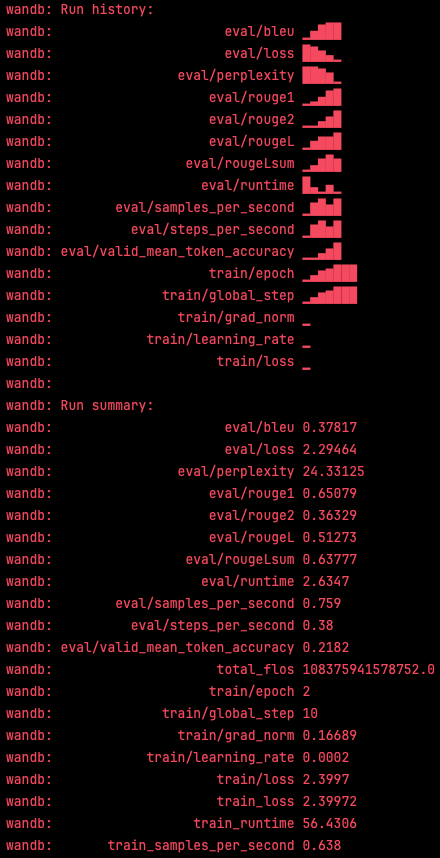
Figure 1: Sample fine-tuning quality metrics used to decide whether a fine tuning deserves promotion to production.
How LLM Monitoring Works
LLM monitoring works by tracking performance, resource usage and response accuracy.
- Monitoring performance: Logs, traces and metrics are used to evaluate response times. When users send a request, they want to receive a quick response. Response time (in milliseconds or seconds) is the time an LLM model takes to respond to a user request.
- Monitoring responses: Checks whether the output is what you expect. Outputs need to be relevant and accurate. Accuracy involves evaluating how often the model is right. Evaluation metrics such as the F1 score can help you determine how the model balances precision and recall.
- Monitoring resource usage: Monitors token usage, which can tell you how efficiently an LLM uses resources. These resources include memory, CPU, network I/O and GPU. LLMs consume input and output tokens, which can be of any size, including just one character or word. You can monitor how the LLM uses these tokens as a cost-control measure by ensuring that the token usage is within set limits.
LLM monitoring works by tracking performance, resource usage and response accuracy.
The Benefits of LLM Observability and Monitoring
LLM observability and monitoring are essential for developers, data engineering and DevOps teams and provide many benefits, including helping them achieve the following:
Faster Error Detection and Diagnosis
Observability and monitoring help developers quickly identify and evaluate root causes when LLMs output includes incorrect responses, response times are slow and API calls delayed. With observability, developers can analyze API calls and back-end operations to diagnose the root cause of an issue. Observability and monitoring provide real-time metrics, logs and traces to allow engineers to resolve issues quickly.
Improved Model Performance and Accuracy
By performing continuous evaluation and monitoring of model outputs, engineers can examine the model’s performance, relevance and accuracy. Engineers can then refine algorithms to improve the accuracy and relevancy of responses. In addition, by observing LLM outputs over time, developers can adjust and retrain models to improve accuracy and address model drift.
LLM observability helps track how data flows through the system while detecting anomalies.
Enhanced Debugging and Troubleshooting
With LLM observability and monitoring, developers get detailed callbacks for query tracing and indexing, which helps debugging speed and accuracy. Developers access detailed insights into the flow of requests to quickly find the root cause of hallucinations and unexpected responses.
Enhanced Security
LLM observability helps track how data flows through the system while detecting anomalies, which helps block unauthorized access while ensuring compliance with security protocols and data handling policies. Observability also helps developers identify areas in the system for potential vulnerabilities and external threats.
Challenges in LLM Observability and Monitoring
Monitoring LLMs comes with unique challenges.
- Training bias and ethical concerns: Data sets with biases will distort observability metrics. To ensure correct model evaluations, users need to be certain that LLM training data sets contain no biases.
- Data volume and complexity: LLMs generate large volumes of data and may suffer from model drift. Monitoring extremely large data volumes at scale — yet alone understanding the logic and internal workings of LLMs — requires automation. Users need automated monitoring and observability solutions to sift through the complexity of LLMs and extract meaningful metrics.
- Observing the model without affecting the model: Monitoring LLMs at scale and in real time demands significant compute resources. You need to find a way to observe and monitor the LLM’s behavior while making sure you don’t affect the model’s performance. It’s hard to strike this balance.
- Dynamic language: The evolution of languages into new linguistic patterns, slang and trends adds to the complexity of LLM monitoring and observability. Monitoring and observability solutions need to continually evolve to ensure LLMs use current linguistic patterns.
Summary
LLM observability and monitoring is critical for LLMs to function optimally and become assets for the enterprise. By their nature, LLMs are largely black boxes for operational teams. Especially when used in an agentic setting, complexity can grow exponentially. Together, the two help developers, data engineering teams and DevOps teams detect and debug errors, track resource usage, detect anomalies and much more. Effective monitoring and observability provide confidence that LLM and LLM-powered applications are secure, performant, reliable and free from bias.
For more information on how BMC Helix supports your LLM observability needs, please contact BMC.
The post What Is LLM Observability and Monitoring? appeared first on The New Stack.




