Quando falamos de processamento de arquivos em larga escala, enfrentamos desafios bem conhecidos, como custos, gerenciamento de processamento distribuído, escalabilidade e eficiência. Além disso serviços de AI geralmente são cobrados por chamada ou quantidade de dados processado, tornando assim os custos de processamento de uma grande quantidade de dados economicamente inviável.
Para esses desafios e trazer uma maior soberania dos dados, apresento um exemplo de arquitetura distribuída baseada em Kubernetes, orientada a eventos, moderna, eficaz e alinhada aos princípios Cloud Native.
A proposta dessa arquitetura é transcrever um grande volume de arquivos de áudio, otimizando ao máximo o uso da GPU. Neste caso, utilizamos a GPU A10.1 da Oracle Cloud (OCI).
Para isso, desenvolvi uma solução orientada a eventos que aproveita os serviços nativos do OCI para emitir eventos e enfileirar as tarefas de transcrição dos arquivos.
O código, escrito em Python, lê os nomes dos arquivos diretamente do OCI Stream ou OCI Queue e os processa em paralelo utilizando a biblioteca Dask . Essa biblioteca permite que vários arquivos de áudio sejam processados simultaneamente em uma única GPU.
A transcrição é realizada por meio do Faster Whisper , utilizando o modelo large-v3-turbo. Os resultados são salvos em um Object Storage de saída.
Esse código é executado no OKE (Oracle Kubernetes Engine) , com as permissões necessárias para ler e escrever arquivos no Object Storage.
Os códigos em Python e instruções para realizar o deploy estão disponíveis neste repositório no GitHub.
Arquitetura Orientada e Eventos
A escolha desta arquitetura foi motivada pela necessidade de desacoplar a transcrição dos arquivos do restante do sistema. Além disso, ela facilita o balanceamento de carga, pois cada consumidor, seja do Stream ou do Queue, processa os arquivos de acordo com sua capacidade e tempo disponível.
Outra vantagem é a escalabilidade horizontal, permitindo adicionar mais consumidores conforme necessário. As ferramentas e bibliotecas que gerenciam as filas garantem que cada arquivo seja processado apenas uma vez, evitando duplicações.
Fluxo da Arquitetura
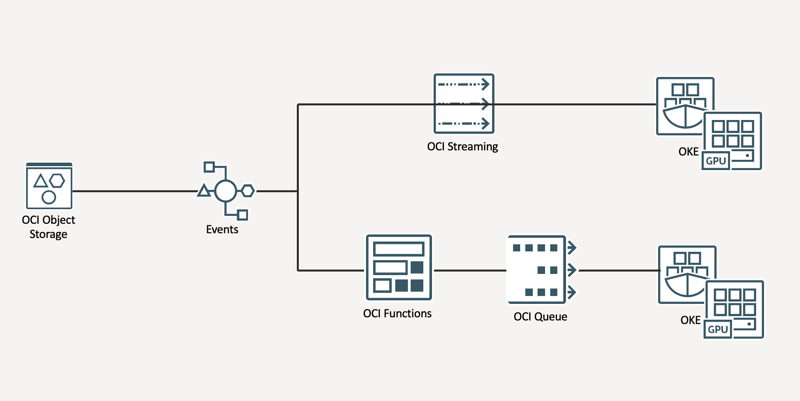
- Um arquivo de áudio é carregado em um bucket de entrada na Oracle Cloud.
- Esse bucket emite um evento de criação de arquivo.
- O serviço OCI Events captura esse evento e inicia uma ação.
- A ação pode ser o envio do evento para um OCI Stream ou a inicialização de uma função para enviar o evento para o OCI Queue.
- Um pod no OKE lê os eventos do Stream ou Queue e inicia o processo de transcrição de cada áudio.
- As transcrições resultantes são salvas em um bucket de saída.
Porque Kubernetes?
O Kubernetes é a plataforma de gerenciamento e execução de contêineres mais amplamente utilizada no mundo. Além disso, é uma das ferramentas fundamentais para projetos Cloud Native, sendo gerenciada pelo CNCF (Cloud Native Computing Foundation).
Kubernetes oferece resiliência e escalabilidade nativas. Caso ocorra alguma falha no nível de nó ou contêiner, novos recursos são criados automaticamente para garantir a continuidade do workload.
Neste caso específico, utilizamos o OKE (Oracle Kubernetes Engine) com Managed Nodes e um cluster configurado com GPU A10.1. Este modelo de GPU disponibiliza apenas um chip gráfico, sem suporte ao MIG (Multi-Instance GPU). No entanto, isso não impede a criação de paralelismo a nível de contêiner.
Dask e a Otimização do uso de GPU
Como mencionado, a arquitetura utiliza um modelo de GPU com apenas um chip gráfico, sem suporte ao MIG. Portanto, o paralelismo deve ser implementado no nível de código.
Para resolver esse problema, a biblioteca Dask surge como uma solução ideal. O Dask é uma biblioteca para processamento paralelo de grandes volumes de dados. Neste caso, foi utilizado para paralelizar a transcrição dos áudios armazenados no Object Storage.
A GPU A10.1 possui 24 GB de memória. O modelo Faster Whisper large-v3-turbo , com precisão de float16, consome entre 3 e 7 GB de VRAM durante a inferência, dependendo do tamanho do arquivo processado. Com base nisso, é possível processar até cinco arquivos simultaneamente, com uma perda de desempenho aceitável no tempo de processamento nos picos de utilização.
Conclusão
Com essa abordagem, conseguimos maximizar o uso da GPU, garantir alta escalabilidade e manter uma arquitetura resiliente e eficiente para processamento de arquivos em larga escala.