“We’re losing about half a million dollars monthly to our broken testing process.” This sobering statement came from a VP of platform engineering during a recent discussion about their microservices testing challenges. What made it particularly concerning was that it wasn’t an estimate — it was the result of careful measurement.
Their organization had grown to over 200 developers working across dozens of microservices, each engineer submitting an average of 15 pull requests monthly. What appeared on the surface to be a thriving engineering organization was concealing a significant productivity drain: Their integration testing was completely disconnected from the PR review process.
“Our developers don’t actually wait for integration tests before merging,” the VP explained. “They run basic unit tests, get code review approval and merge. Then the real problems begin.”
Their post-merge integration and end-to-end testing frequently revealed issues that weren’t caught by unit tests. When failures occurred — which happened regularly — engineers had to context switch back to code they’d mentally moved on from, diagnose complex integration problems and run through the entire PR cycle again.
“Each debug-fix-merge cycle can consume one to two hours of focused engineering time,” the VP continued. “With engineers hitting these integration failures regularly, we’re seeing around 20 hours per developer per month lost to this fragmented workflow.”
The math was sobering: 200 engineers × 20 hours lost monthly × $100 per hour = $400,000 in engineering productivity vanishing every month.
When I suggested the traditional solution of spinning up more environments to alleviate the bottleneck, the VP shook his head. “We’ve run those numbers repeatedly. The infrastructure costs for duplicating environments would approach our current losses, without solving the fundamental problem.”
This conversation epitomizes the dilemma that modern microservice architectures have created for engineering teams. Organizations adopt microservices for scalability and team autonomy, only to find themselves wedged between mounting infrastructure costs and diminishing developer productivity.
The Inner Loop vs. The Outer Loop
To understand why this problem is so pervasive, we need to examine what engineers call the “inner loop” and “outer loop” of development.
The inner loop — writing code, running unit tests and making local changes — is typically fast. Engineers get immediate feedback in minutes. This rapid cycle is where developers thrive, maintaining flow state and high productivity.
But with microservices, the outer loop — integrating changes with other services, running full system tests and deploying — becomes dramatically slower, often by a factor of 10 times or more.
Let’s break down why this outer loop becomes a productivity killer:
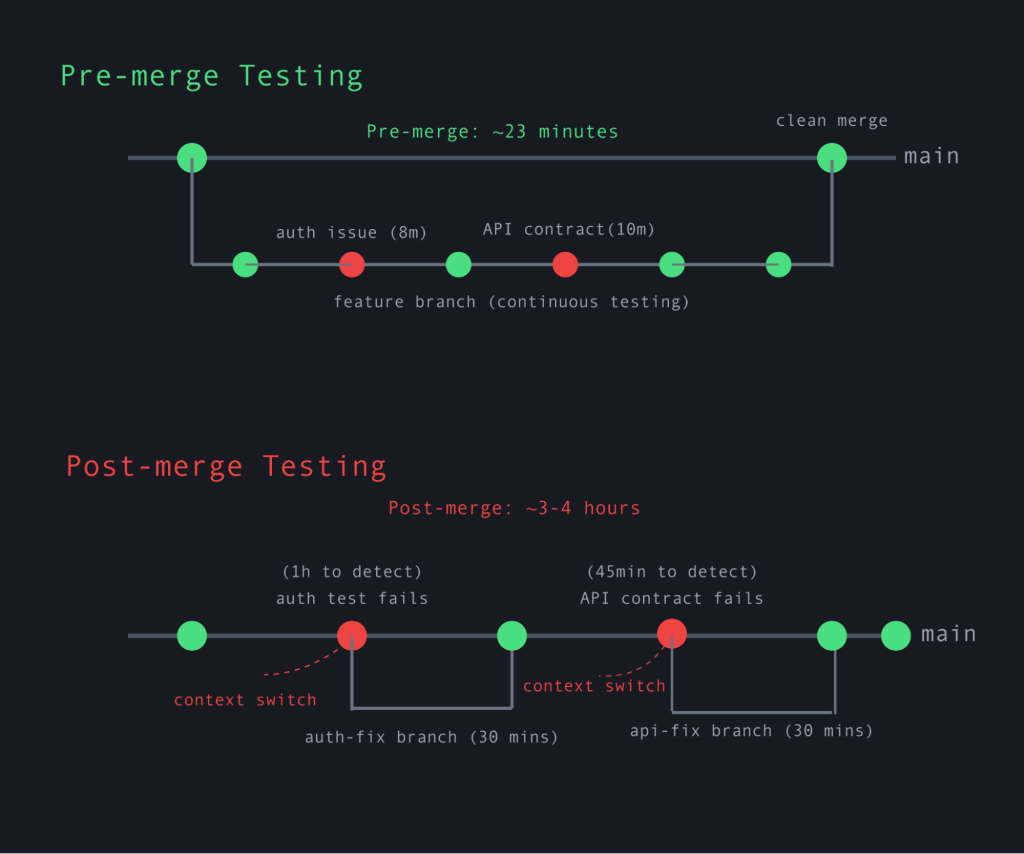
- The integration bottleneck: Once code passes review and basic unit tests, it’s merged into the main branch. Only then do comprehensive integration tests run — often in a shared staging environment alongside dozens of other recently merged changes.
- The murder mystery: When tests fail in this environment, engineers face a detective challenge. Was it their change? Was it someone else’s change? Was it an interaction between multiple changes? With dozens of commits merged since the last successful run, pinpointing the culprit becomes a time-consuming investigation.
- The context switch penalty: By the time integration failures appear, engineers have mentally moved on to new tasks. Switching back to debug code written hours or days ago incurs a significant cognitive cost. Studies show it can take up to 23 minutes to fully recover focus after a context switch.
- The queue effect: Some organizations try to mitigate these problems by creating strict staging environment access controls. One engineering director shared that they built a custom Slack bot for queuing access to staging. Engineers would type “/staging-queue add” and wait for their turn — sometimes for hours. On Fridays, with everyone rushing to merge before the weekend, wait times could stretch to four or five hours.
- The ripple effect: Failed tests don’t just affect the responsible developer. When staging environments break, entire teams can be blocked. One failed deployment can derail multiple workstreams.
The cumulative impact is staggering. A typical debug-fix-test cycle in the outer loop might consume two to three hours, versus two to three minutes in the inner loop. With engineers hitting these cycles multiple times weekly, companies routinely lose eight to 10 hours per developer per week to this fragmented workflow.
Traditional Approaches Don’t Scale
Why can’t we solve this with more environments? The conventional “system in a box” approach, where each developer spins up the entire system in their own isolated cloud instance, quickly becomes prohibitively expensive at scale.
Let’s do the math:
For a system with 50 microservices, a developer needs a beefy AWS EC2 m6a.8xlarge instance (32 vCPUs, 128 GiB memory) that costs approximately $1.30 per hour. Running this 24/7 for a month costs $936, or $11,232 per year for a single developer environment. To provide dedicated environments for a team of 50 developers, the annual cost skyrockets to $561,600 — and that’s just for compute, not including storage, data transfer or managed services.
This is why many teams settle for a constrained number of shared environments, creating bottlenecks and productivity drains.
A Modern Approach: Tenancy-Based Environments
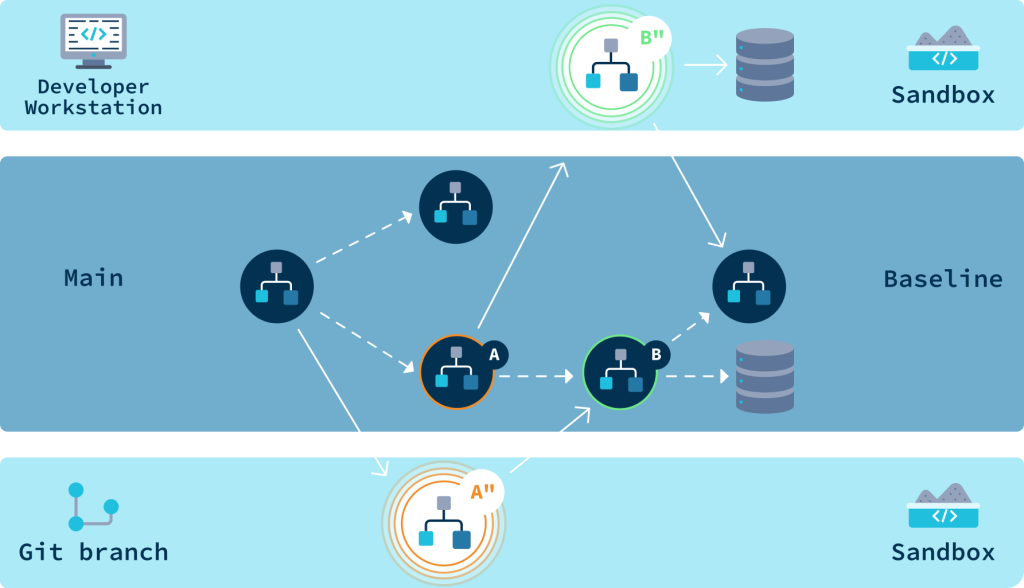
Sandboxes encapsulating local and git branch versions of services.
Modern service mesh architectures are changing this equation:
Instead of duplicating infrastructure, you can create instant test environments by isolating at the request level using service mesh technology. Each developer gets their own sandbox through smart request routing.
Here’s where the transformation becomes quantifiable:
- Infrastructure costs: Down 90% compared to duplicating environments, making it economically feasible to provision isolated testing for every PR
- Testing scope: From selective testing (due to resource constraints) to comprehensive testing for every code change
- Integration testing speed: From post-merge (hours) to pre-merge (minutes)
- Developer iterations: From one or two per day to 10 to 15 per day
- Mean time to resolution: From two to three hours to 15 to 20 minutes
- Defect escape rate: Reduced by 70% (issues caught before merge)
The most dramatic impact comes from dramatically reducing the cost of ephemeral environments. When testing becomes affordable at scale, organizations can shift from rationing testing resources to providing on-demand environments for every pull request. This democratization of testing transforms both developer productivity and software quality without breaking the infrastructure budget.
The VP’s response: “So we can give every developer instant environments AND reduce costs?”
Yes, exactly!
How Does This Work?
The key insight is that full environment duplication is unnecessary for testing microservices. With application-layer isolation and smart request routing, you can share the underlying infrastructure while maintaining isolation.
When a developer wants to test a change, the system creates a sandbox that includes only the services being modified. Requests are dynamically routed to these sandboxed services based on request headers, while using the shared environment for everything else.
Addressing the Data Isolation Challenge
One crucial aspect of this approach is how to handle data isolation. When engineers first hear about request-based routing, they immediately raise concerns about the data layer: “If we’re sharing infrastructure, won’t concurrent tests interfere with each other’s data?”
This is a valid concern with multiple solutions depending on the testing requirements:
For most testing scenarios, shared databases work remarkably well. The key is leveraging the multitenancy patterns that are often already built into microservice architectures. By partitioning test data using existing domain model identifiers (userId, orgId, tenantId), each test can operate in its own logical space within the shared database.
For more intensive testing needs, like schema migrations or data-destructive operations, temporary database instances can be provisioned on demand. These ephemeral databases spin up only when needed and terminate when testing completes, providing complete isolation without the overhead of maintaining permanent duplicate infrastructure.
The most sophisticated systems offer a hybrid approach, automatically determining when shared resources are sufficient and when isolated resources are required. This gives developers the best of both worlds: the speed and efficiency of shared resources with the safety of isolation when necessary.
Proven in Production
This approach isn’t just theoretical; it’s already delivering results at scale. Leading tech companies have implemented variations of this model with impressive outcomes:
- Uber built SLATE for request-based routing of test traffic.
- Lyft created a control plane for its shared development environment.
- Airbnb implemented request routing that significantly reduced testing costs.
These organizations use cloud native technologies and service mesh capabilities to transform testing without duplicating infrastructure. The most advanced implementations use Infrastructure as Code (IaC) to provision ephemeral environments in minutes — not just for testing, but for prototyping and experimental development too.
The business impact is measured through both technical metrics (e.g., the DORA framework) and developer experience improvements. Companies typically see faster time to market, higher quality releases and dramatically lower infrastructure costs, delivering the rare combination of better, faster and cheaper software development.
From Bottleneck to Breakthrough
The traditional approach of post-merge integration testing creates an unnecessary bottleneck in microservices development. By shifting integration tests left — moving them from the slow outer loop into the rapid inner loop — organizations can fundamentally transform their development process.
Engineers verify changes against real dependencies before merging, catching integration issues when they’re still fresh and inexpensive to fix. Modern cloud native technologies like service meshes and request routing make this approach increasingly accessible without requiring massive infrastructure investments.
For organizations struggling with microservices testing, this transformation delivers a clear competitive advantage: higher-quality software, faster delivery cycles and more efficient resource utilization — all while improving the developer experience.
The post The Million-Dollar Problem of Slow Microservices Testing appeared first on The New Stack.