
Large Language Model (LLM)-based Generative AI services such as OpenAI or Google Gemini are better at some tasks more so than others, advised Wei-Meng Lee, technologist and founder of Developer Learning Solutions, in ACM TechTalk last month, entitled “Unlock Hugging Face: Simplify AI with Transformers, LLMs, RAG, Fine-Tuning.”
For instance, the LLMs are not good at performing analytical tasks, surprisingly enough. And even if you did want to use an LLM for the task, it’d probably be prohibitively expensive, given the size of your data set.
Say you have a CSV file with 20 columns and five million rows. It may include transaction records, as well as customer data. You want to ask a question such as what did this customer purchase on one particular day. How much did you earn this month? Is this easy work for the LLM?
“The thing is, no,” Wei Meng explained. “LLMs are very bad at analytical tasks.”
Certainly, LLMs are very good at text-based questions and extracting information from large, unstructured bodies of text. However, numerical analysis is still a challenge.
But there is a way you can still use LLMs for such tasks.
Tokens and Dollars
The information that the user provides and the answers received when interacting with a GenAI chat service is known as the “context window size.” This is usually measured in tokens.
Roughly speaking, one token roughly equals 3/4ths of an English word. Parts of words can be whole tokens, with the prefixes and suffixes making up their own tokens.
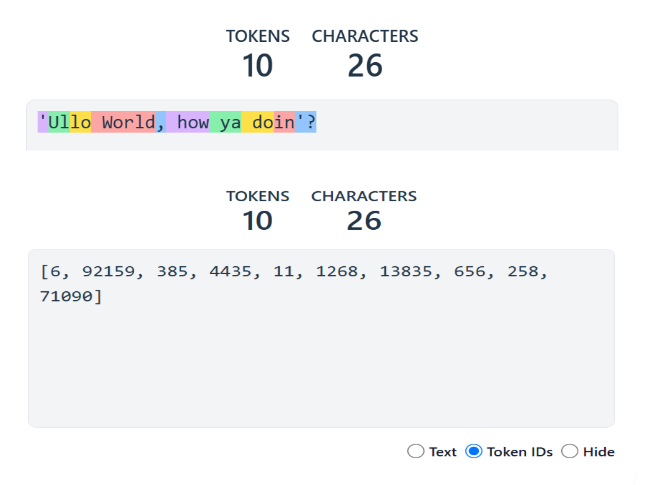
An example of tokenization from a Hugging Face course on building AI Agents.
Services have different context size windows. OpenAI‘s GPT-40-mini has a content window size of 128,000 tokens, or about 96,000 words and associated characters, with the both the question and answer.
So, you must stuff your entire question, along with all the supporting data, into the context window.
“For normal chat, not a problem,” Wei Meng said.
But if you are using really large data sets, this will cost you!
A 20-column five million row CSV value file will chew through that token window rapidly.
Exceed the context window size, and you will get an error message or incur extra fees.
Also shipping your data outside puts the privacy of your data at risk.
Do This Instead
Instead of sending an entire data set, keep the data on your server. Then, formulate the prompt by including a description of the format of the dataset, perhaps with the schema itself, and maybe even a few sample, anonymized, examples.
Then, instead of asking the GenAI to answer your questions, ask the GenAI to generate the code or queries necessary to answer them.
Then, you execute the code in your local environment.
“You do not violate the context window size. You do not sacrifice the privacy of your data,” he said.
In an example, Wei Meng said showed how one could analyze the dataset of all the passengers aboard the ill-fated Titanic voyage, using OpenAI and the LM Studio. A CVS file with the data — which had 891 rows and 12 rows — was loaded into a Python DataFrame.
Here is the prompt he then gave OpenAI:
{
'role':'userf',
'content':'''
Here is the schema of my data:
PassengerID,Survived,Pclass,Name,Sex,Age,Sib5p,Parch,Ticket,Fare,Cabin,Embarked
Note that for Survived, 0 means dead, 1 means alive
Return the answer in Python code only
For your info, I have already loaded the CSV file into a dataframe named df
'''
}
In general, the more descriptive the prompt, the better answers you’ll get, Wei Meng advised.
Once all the prompts are loaded in, you can ask your questions, such as
- What is the proportion of male and female passengers?
- Can you visualize the survival rate for each passenger class (Pclass)?
- Can you visualize the survival rate of passengers traveling alone vs. with family?
Note that the answers do not need to be text-based if you have, in this case, the Python visualization tools on hand.
Using a Jupyter Notebook or LM Studio, you could even automate the execution of the query yourself, with results displayed back in the workspace as soon as it is returned.
“The nice thing is that you don’t have to upload the data, or learn data analysis,” he said.
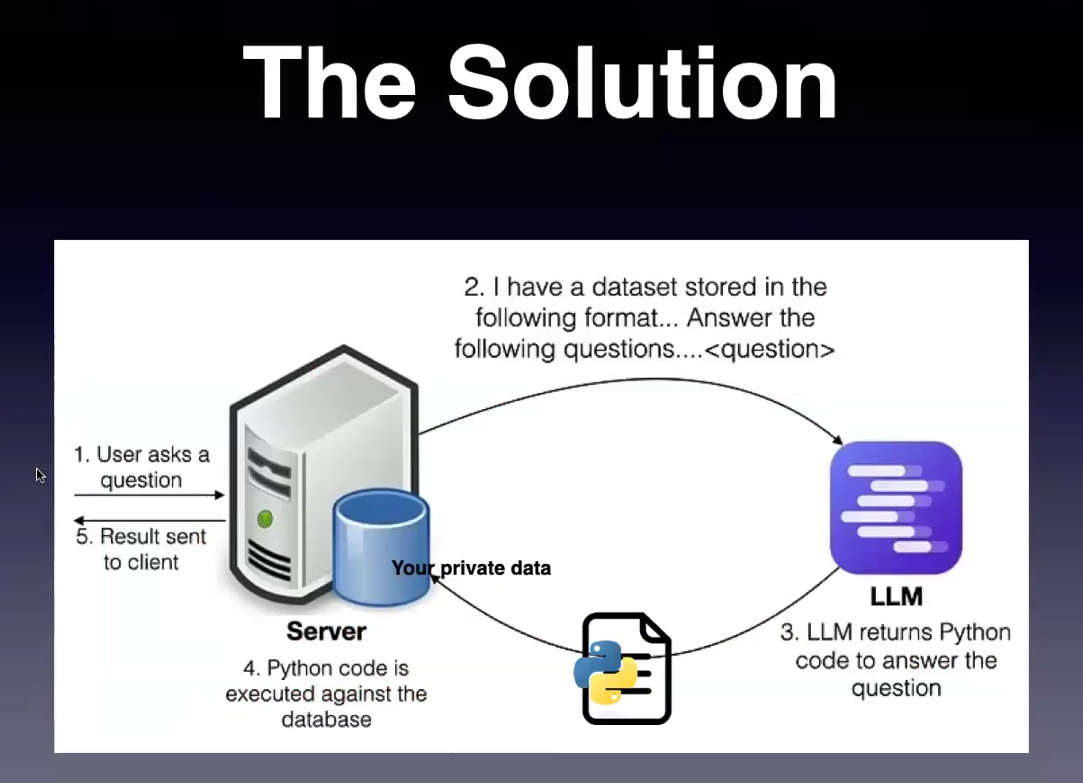
From the Hugging Face presentation by Wei-Meng Lee.
What Is Hugging Face?
Wei-Meng Lee’s presentation concerned itself chiefly with how to use Hugging Face, a collaborative platform for developers and researchers to use and collaborate on machine learning models, datasets and applications.
In the presentation, Wei-Meng showed how to use Hugging Face’s pre-trained models through the company’s Transformers API. Hugging Face’s pipeline objects can then ease the task of using these models, he then goes on to demonstrate. And he shows how to use the Gradio library to easily run LLM-based Python applications.
“Gradio allows you to build a very nice web frontend with just a couple of lines of code,” Wei-Meng said.
The post Save Valuable GenAI Tokens With This One Simple Trick appeared first on The New Stack.
Comments are closed.