Data Locality, where computation is moved closer to the nodes where data resides to remove performance bottlenecks and speed up round-tripping, has been essential to the evolution of modern distributed computing system design.
It was largely popularized within the Big Data movement and rethought again around data processing optimization from the early days of MapReduce and Hadoop up through the more modern era of Apache Spark and streaming data. The need for applications to process extensive real-time data flows in parallel sparked new thinking about application infrastructure, driving new approaches to tricky challenges like state, concurrency, async/backpressure, and more into programming language primitives and frameworks. Data Locality has also become fundamental to the cloud native era, where the most exciting use cases have broadly evolved from data “at rest” to data “in motion,” from “batch processing” to “real-time processing” — and from stateless to stateful workloads.
These changes put us in the early days of a new renaissance — this time at the system intelligence level. For decades — as our application architectures (from monolith to microservices) and system architectures (from single machines to cluster) became ever more distributed — somehow, the systems of intelligence that we use to operate, secure, and observe our environments have remained trapped in centralized architecture models.
A new era of “distributed intelligence” is blooming in system architecture, seeking to bring intelligence closer to the data. Let’s examine why this trend is happening, the central role that eBPF is playing in enabling fresh thinking in systems architecture, and the implications of much tighter round-tripping between system data and intelligence.
Cracks in the Centralized Intelligence Model
In an IT world driven by centralized decision-making, gathering insights and applying intelligence often follows a well-established — yet limiting — pattern. At the heart of this model, large volumes of telemetry, observability, and application data are collected by “dumb” data collectors. For analysis, these collectors gather information and ship it to centralized systems, such as databases, security information, event management (SIEM) platforms, or data warehouses.
With the exponential growth in data and infrastructure complexity, the cracks in this model are now beginning to show.
One of the most significant drawbacks of this approach is data transfer overhead. The more data that needs to be collected, the larger the strain on the infrastructure and the network, as the information must be transmitted from the point of origin to the central point where the decisions are made. This also increases latency between when the data is generated and when decisions can be made. In scenarios where real-time responses are crucial, such as threat detection in security or performance tuning in networking, this lag can inhibit effective operations.
The scalability of what was initially designed as scalable systems can also be impacted. As infrastructure grows and becomes more distributed, the data generated increases exponentially. Centralized intelligence systems must scale in data storage and computational capacity to process and analyze this information, resulting in significant infrastructure costs as more powerful hardware, larger databases, and faster networks are required to keep up. More data also increases the “data gravity” — we’ve collected it, stored it, and now there’s so much of it it’s hard to move. This infrastructure expansion to meet the needs of the expanding infrastructure approach can quickly become unsustainable, forcing organizations to choose between insight and cost. Transferring raw data to centralized locations often leads to unnecessary processing and storage. Instead of filtering or processing data at the source, vast amounts of irrelevant or redundant data are transferred and stored, wasting valuable resources. This inefficiency is only exacerbated as data grows, resulting in over-engineered analytics systems and increased operational complexity.
Finally, even if infrastructure cost was not an issue, the contextual disconnection between where the data is generated and processed further reduces centralized intelligence’s benefits. When data is aggregated and analyzed, it often lacks the immediate context that would enable more informed decision-making. Critical information about the system state, environment, and workload conditions is diluted or lost during transit, leading to less accurate awareness of the situation.
Constraints to Networking, Security and Observability Systems
The failures of the centralized intelligence model — data transfer overhead, latency, scalability challenges, and loss of contextual insight — are particularly pronounced for platform teams’ networking, observability, and security use cases. Let’s see how these challenges played out across various levels of centralized control.
Networking
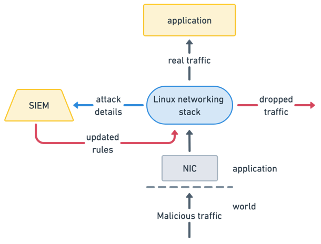
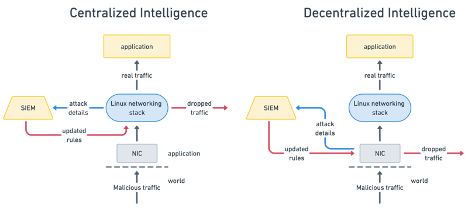
The traditional Linux network stack struggles in distributed environments, as its centralized, linear pipelines introduce latency and inefficiencies when handling high traffic volumes or dynamic workloads. The rigid structure limits adaptability for real-time needs like load balancing, connection tracking, and custom protocols. These are becoming particularly evident in scenarios like DDoS mitigation or edge computing, where vast amounts of traffic must be handled precisely and quickly. Conventional solutions often rely on centralized traffic processing at choke points, such as routers, firewalls, or load balancers. These points become bottlenecks as they struggle to analyze and manage real-time traffic flows. For example, the data must typically traverse the entire network stack to filter malicious packets before reaching user-space applications or external systems like intrusion detection platforms. This introduces significant latency and increases the likelihood of overloading resources, particularly in high-throughput environments.
Moreover, traditional approaches often depend heavily on predefined rules and static configurations, making them inflexible when dealing with dynamic and distributed traffic patterns. Scaling these systems requires replicating centralized control points across multiple nodes or regions, which increases complexity and infrastructure costs. Additionally, the delay introduced by the need to export data for analysis or apply security logic in user space undermines the real-time responsiveness required to protect against fast-evolving threats like DDoS attacks. These limitations illustrate the inherent inefficiency of centralized networking models in modern distributed environments, where speed, scalability, and adaptability are paramount.
Observability
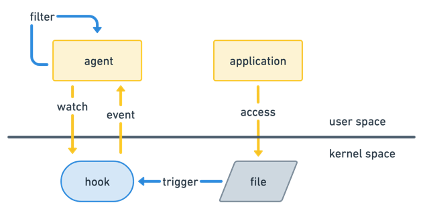
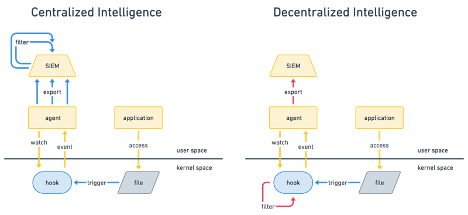
Traditional observability models relied on capturing large volumes of system events or logs and transferring them to a centralized observability system for filtering, analysis, and storage. This approach, while functional, introduces significant inefficiencies. Large volumes of raw data — such as system calls, network activity, and process events — must be transferred into the centralized system, where they are filtered to identify the relevant insights. This process incurs high CPU and memory costs and delays real-time analysis, as every event must pass through multiple stages before being processed. Additionally, since irrelevant data is transferred alongside meaningful events, the overhead can strain system resources, making it challenging to scale effectively in environments that generate many events, such as cloud native systems.
Security
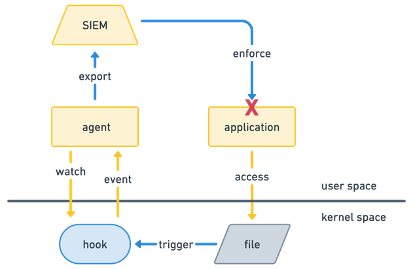
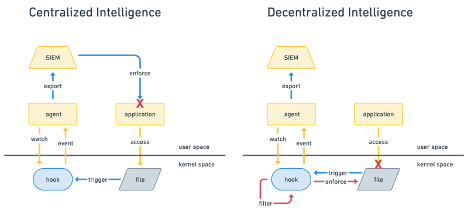
In traditional security monitoring systems, threat detection relies on user-space agents or tools that collect data from logs, network traffic, and system events for analysis. After gathering, this data is typically sent to a centralized Security Information and Event Management (SIEM) system for further processing and correlation. This entire pipeline introduces multiple layers of delay: first, transferring events from the kernel to user space; then, exporting them to an SIEM for aggregation and analysis; and finally, requiring a human or automated system to act on the findings. The time gap between an event’s occurrence (time of check) and its detection and response (time of use) creates a vulnerability similar to Time of Check, Time of Use (TOCTOU) attacks, where an attacker can exploit the window of delay to carry out malicious actions undetected. Moreover, in high-traffic environments, resource exhaustion can result in dropped events, increasing the chances of missed security incidents, as crucial data may never even reach the SIEM for analysis.
The limitations of the centralized intelligence model — data transfer overhead, latency, scalability issues, and loss of contextual awareness — are starkly evident in these networking, observability, and security use cases.
Flipping the Model to Distributed Intelligence with eBPF
With eBPF, we can process, filter, and act on data as it flows through the system — directly at the kernel level. This architecture approach flips the centralized model on its head by embedding decision-making directly into the system at the point where data is generated. This means that instead of forwarding vast amounts of raw data for centralized processing, we can use intelligent, kernel-embedded programs to analyze, process, and act on data exactly where it was generated in real-time. By doing this, eBPF enables a shift from centralized, reactive decision-making to distributed, proactive intelligence.
By processing data at its origin, we significantly reduce the amount of unnecessary or irrelevant data sent over the network, resulting in lower information transfer overhead. This minimizes the load on the infrastructure itself and cuts down on data storage and processing requirements. The scalability of our systems no longer needs to hinge on the ability to expand storage and analytics power, which is both expensive and inefficient. With eBPF, distributed systems can now analyze data locally, allowing the system to scale out more efficiently as each node can handle its own data processing needs without overwhelming a centralized point of control — and failure. Instead of transferring and storing every piece of data, eBPF can selectively extract the most relevant information, reducing noise and improving the overall signal quality.
Moreover, this approach introduces a new level of contextual awareness. Since eBPF runs directly in the kernel, it has access to the system-wide context that a centralized model might miss or not have access to. Decisions made at the source are informed by real-time, localized conditions, resulting in more accurate and relevant actions. The intelligence embedded in the system can adjust dynamically based on the immediate environment, making it far more adaptive and responsive to changes and making speed a defining feature of this new approach. Instead of waiting for data to be transferred, aggregated, and analyzed at a central hub, eBPF programs can respond immediately to events as they occur.
This is especially valuable in scenarios like security threat detection, where every millisecond counts, or in network optimization, where rapid, dynamic adjustments can prevent bottlenecks. Let’s take a look back at the same networking, observability, and security use cases and see how eBPF is overcoming the limitations of centralized intelligence and forging new efficiencies:
Networking
Cloudflare’s use of eBPF and XDP demonstrates how distributed intelligence can overcome the challenge of centralized intelligence in distributed networking. While mitigating a record-breaking 3.8 Tbps DDoS attack, Cloudflare leveraged XDP to inspect and filter packets within the network interface card (NIC) itself at the earliest possible point. Malicious traffic was dropped immediately before it could traverse the kernel networking stack, significantly reducing processing overhead and freeing up resources for legitimate traffic. This approach enhanced scalability and allowed for real-time responses critical in high-pressure scenarios.
By allowing custom logic to be injected dynamically into the kernel, eBPF allowed Cloudflare to adapt rapidly to changing attack patterns without requiring system restarts or kernel modifications. They could update their filtering logic to respond to the specific characteristics of the attack in real time, ensuring malicious packets were identified and blocked effectively. This ability to adapt on the fly transforms DDoS mitigation from a reactive process into a proactive one, enabling the network to stay ahead of attackers.
The combination of eBPF and XDP exemplifies how distributed intelligence redefines networking performance and security. By bringing decision-making closer to the traffic source and enabling dynamic adaptability, platforms like Cloudflare can mitigate massive attacks efficiently and maintain operational stability, even under extreme conditions. Distributed intelligence represents a decisive shift in how modern distributed systems handle large-scale networking challenges.
Observability
In-kernel filtering with eBPF changes the observability paradigm. Instead of collecting and transferring all system events to a centralized system for filtering, eBPF allows us to monitor critical system events — like process execution, network connections, and syscall activity — and instantly discard irrelevant data directly at the source in the kernel, minimizing the data sent to centralized observability systems. This ensures that only relevant events are passed on for further processing, minimizing resource consumption and improving real-time responsiveness. Filtering at the source also benefits from access to immediate system context, enabling more accurate decisions about critical events, thus optimizing both performance and scalability in observability. It also reduces the amount of “noise” in the centrally stored observability system, reducing resource strain.
Tetragon provides some benchmarking of the benefits of kernel filtering, and the results are dramatic. When observing file integrity for a highly I/O-intensive workload but where there was no suspicious activity, user space filtering (without even considering exporting to an additional centralized observability system) added 3.6% overhead, while in-kernel filtering only 0.2% overhead — a 17x increase in performance. Similarly, monitoring all network activity by tracking new connections made and ports opened was 2.5x more efficient in the kernel.
Security
Using eBPF tackles these challenges by embedding security logic directly in the kernel, enabling real-time detection and response at the source of the event. By processing events such as unauthorized system calls or privilege escalation attempts in the kernel, eBPF closes the TOCTOU window by acting instantly without needing to export data to user space or wait for SIEM analysis. Additionally, eBPF’s in-kernel filtering ensures that only relevant security events are passed to user space, reducing data transfer overhead and minimizing the risk of resource exhaustion, even under heavy load. Since decisions are made in real-time and in-kernel, eBPF eliminates the delays typically associated with forwarding data to an SIEM and waiting for a human response, allowing immediate action in critical scenarios such as blocking exploits or stopping lateral movement in a network. This approach reduces latency and ensures that security events are reliably detected and mitigated in real time, even under extreme system loads.
Looking at examples across networking, observability, and security from deep within the kernel to interacting with external SIEM systems, moving the system intelligence closer to the data has a benefit at every level. The failures of the centralized intelligence model — including data transfer overhead, latency, scalability concerns, and the loss of contextual insight — are addressed by embedding intelligence directly into the kernel with eBPF, where decisions can be made in real time at the source of data generation.
It’s the Data, Stupid
A famous political campaign slogan, “It’s the economy, stupid,” speaks to the bottom line, where the contest would be won or lost.
For platform teams, despite all other efforts and mission creep, the ability to translate data into value determines a company’s success. It’s the Data, stupid.
From training ML models, to interpreting IoT sensor data to something as fundamental as observing user data for extremely popular web-scale services or serving e-commerce stores — it’s become table stakes for our systems to process large real-time data flows in parallel. It’s taken a long time, but the classic Data Locality principle extends from just the application to the systems and overall architecture we use to manage and secure our environments.
The shift to bringing intelligence directly to the data with eBPF represents a fundamental evolution in how we design and manage cloud native infrastructure and distributed systems. eBPF allows for offloading complex computations and decision-making to the edge of the infrastructure, where data is generated. By embedding intelligence at the kernel level, eBPF also enables real-time, localized data processing, reducing the inefficiencies of centralized models and minimizing data transfer overhead.
This distributed intelligence model enhances scalability and efficiency and introduces greater contextual awareness and faster decision-making. eBPF’s ability to dynamically respond to data at its origin will be crucial in driving the next generation of secure, scalable, and highly adaptive infrastructure. eBPF is already becoming the core enabler of the next generation of cloud native architectures, and the shift toward distributed intelligence will only accelerate its adoption. Distributed intelligence with eBPF is poised to revolutionize how we think about infrastructure management for the years to come.
The post Rethinking System Architecture: The Rise of Distributed Intelligence with eBPF appeared first on The New Stack.