Engineering leaders face increasing pressure to integrate AI into software development while balancing model selection, performance optimization, security and cost efficiency. Traditional fine-tuning approaches demand significant resources and struggle to keep pace with evolving enterprise codebases. Meanwhile, intelligent routing systems and expert models introduce complexity and scalability concerns.
The challenge lies in deploying AI solutions that provide accurate, context-aware recommendations while maintaining flexibility and efficiency across diverse development environments. This article explores the advantages and limitations of various AI model strategies — mixture of experts (MoE), fine-tuning, retrieval-augmented generation (RAG) and hybrid approaches — offering a framework for selecting the most effective solution for enterprise software engineering.
Integrating LLMs and SLMs
Integrating small language models (SLMs) and large language models (LLMs) for software engineering tasks optimizes efficiency by leveraging the strengths of both. This hybrid approach benefits tasks such as code generation, debugging and documentation through methods like MoE models, task-specific adapters and collaborative algorithms.
Mixture of Experts (MoE) and Task-Specific Adapters
MoE architectures employ a gating mechanism to assign tasks dynamically to the most appropriate model. This approach optimizes efficiency by allocating simpler tasks to smaller models and complex ones to larger models. Similarly, task-specific adapters enhance LLM performance by enabling smaller models to act as intermediaries for specialized tasks within the software development life cycle (SDLC).
Collaborative Algorithms and Co-LLM
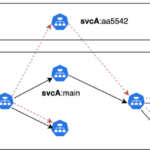
Collaborative algorithms — such as Co-LLM, developed by MIT CSAIL — improve LLM accuracy by selectively invoking expert models when needed. A “switch variable” determines when to engage expert input, enhancing factual accuracy while minimizing computational overhead.
Unlike traditional methods requiring simultaneous model execution, Co-LLM selectively activates expert models for specific tokens, optimizing resource use. This approach has demonstrated success in fields such as biomedical data and mathematics, outperforming stand-alone fine-tuned LLMs.
Intelligent Routing in MoE Systems
Intelligent routing assesses query complexity to determine whether a general-purpose model can handle that query or if a specialized model is required. At the token level, this technique selectively invokes expert models for accuracy-critical queries. However, implementing this approach in enterprise software development presents challenges. Effective use requires ongoing feedback mechanisms, fine-grained control over routing configurations and the ability to override incorrect responses.
A fundamental limitation of this approach is that LLMs and SLMs depend on static training data, making them inherently outdated and lacking contextual awareness of evolving enterprise codebases. To maintain effectiveness, enterprise teams would need to continuously fine-tune multiple expert models across various programming languages, libraries, dependencies, security policies and architectural patterns. This process incurs high computational costs and resource overhead, making it impractical given the rapid pace of codebase evolution.
RAG as a Scalable Alternative
RAG provides a more efficient and scalable alternative by dynamically retrieving external data in real time. This ensures that responses remain accurate, timely and contextually relevant without the need for extensive fine-tuning. Unlike static model fine-tuning, RAG enables adaptation to task-, user-, project- and organization-specific contexts without requiring multiple specialized models.
RAG in Enterprise Software Development
Consider a developer assigned a Jira issue requiring updates to a frontend, backend and microservices architecture. With an intelligent routing approach, the developer would need access to multiple fine-tuned models, and each of them may already be outdated due to ongoing development changes. This approach is inefficient in terms of both computational resources and deployment complexity.
Alternatively, with a RAG-based system, thousands of developers could rely on a single performant LLM. If security and privacy are priorities, an enterprise could deploy an open source LLM on premises, reducing operational costs solely to hardware and energy consumption. A virtual private cloud (VPC) deployment also offers a fully private and secure deployment approach that is cost effective without requiring hardware procurement.
When a model is deployed within an AI software development platform, developers can leverage context-aware selection mechanisms to direct the RAG architecture toward the most relevant combination of context sources for the task at hand from their local workspace, images, and non-code and codebase sources. This controlled contextualization improves code quality without the resource burden of model fine-tuning.
Research from the University of Singapore indicates that RAG is among the most effective methods for reducing hallucinations in LLM responses. In real-world enterprise settings, sophisticated RAG implementations have demonstrated up to an 80% improvement in code quality while operating within a self-contained, on-premises or VPC-based deployment model.
A contextualized agentic workflow utilizing RAG through an AI software development platform would look like this in practice:
- Clone a frontend project into the workspace, allowing the AI platform to index the project’s context.
- Select the Jira issue and image contexts to feed acceptance criteria into the LLM for accurate initial implementation.
- Use repository context to identify relevant microservice files, reducing redundant code generation and preventing technical debt.
- Dynamically select contextual data sources, ensuring precise and task-relevant code recommendations.
By structuring contextual inputs in this way, RAG effectively delivers the benefits of fine-tuning without requiring extensive model retraining. This approach gives developers direct control over contextualizing LLM responses, improving accuracy and efficiency.
Context Awareness Through RAG and Fine-Tuning
The choice between RAG and fine-tuning depends on specific engineering use cases. Enterprises benefit from flexible, configurable hybrid approaches, which are driving the development of AI software development platforms. These platforms provide control over model selection, contextual sources, deployment configurations and agentic workflows, allowing engineering teams to tailor AI implementations to their needs.
SLMs for Specialized Code Completion
SLMs are particularly well-suited for fine-tuned code completions in specialized domains. Thousands of engineers in industries such as semiconductor manufacturing (using Verilog), aerospace and defense (using assembly, Ada or Rust), and government (using COBOL) rely on fine-tuned SLMs for their precision and auditability. These models are cost-effective for on-premises deployments, capable of running even in air-gapped environments.
Recent advancements in reasoning models, such as OpenAI o3-mini, demonstrate the effectiveness of combining SLMs with RAG for agentic code validation and review. By ingesting rule-based databases, reasoning models validate code against predefined architectural, security and performance standards, providing actionable recommendations within pull requests.
LLMs for Deep Reasoning and Broad SDLC Applications
LLMs excel in deep reasoning, complex debugging and full-scale code generation. Due to their broad knowledge base, a single LLM can support multiple programming languages, paradigms and architectures, reducing the need for multiple fine-tuned models. Deploying an LLM within an AI software development platform and augmenting it with RAG enhances accuracy, eliminates hallucinations and optimizes resource efficiency.
By integrating context engines and SDLC agents, AI software development platforms enable precise and context-aware AI-driven software development. These platforms improve code translation, complex debugging, architectural consistency, refactoring, test generation, documentation and developer onboarding, without the need for extensive model fine-tuning.
A Configurable Hybrid Approach
For highly regulated and specialized industries, AI software development platforms provide the most viable solution. Their configurability allows enterprises to govern model selection, fine-tuning, agentic workflows and RAG-based contextualization. This approach grants full control over AI deployment while helping ensure efficiency, security and adaptability in enterprise software development environments.
The post RAG and Model Optimization: A Practical Guide to AI appeared first on The New Stack.