
Data lakes have become a critical component of many organizations’ hopes for business analytics, product execution, and observability. As organizations become aware of the importance of data lakes for observability, a widening chasm is emerging between those who can adequately take advantage of data lakes with the right platforms and those who cannot.
In other words, data lakes have emerged as a necessity instead of the next shiny object for observability. They serve as a single repository for data required for monitoring and debugging purposes, while the real magic they provide is inferences, deep analytics, and discovering problems long before they occur in ways not possible without a data lake. Achieving maximum observability is also arguably contingent on properly applying AI to the telemetric data in a data lake.
According to Gartner’s definition, a data lake is a semantically flexible data storage repository combined with one or more processing capabilities. Gartner analysts Masud Miraz and Roxane Edjlali write in Gartner’s Hype Cycle for Data Management. “Most data assets are copied from diverse enterprise sources and stored in raw and diverse formats to be refined and repurposed repeatedly for multiple use cases.
Organizations are already missing out if they do not have a data lake strategy in place, and many may be surprised at how feasible and accessible data lakes are for observability.
Utility aside, a proper data lake and observability platform are hard to deliver and sets the bar for observability players even higher. Organizations’ needs vary by size, industry, and other factors. Still, any solution must offer a combination of analytics, data compatibility and integration, storage, cost optimization, and other features—and sadly, most do not.
All In
Creating a data lake should not mean that an organization has to completely re-instrument its data flows and develop separate ingresses and APIs for a data lake to accommodate separate data streams for the telemetry data they require. An observability data lake should be able to accept data from the entire application stack and build the integration of these different data sets to create context. Without the wide range of data collections a data lake offers, there is a lack of flexibility in bringing data from the entire application stack from telemetry data sources.
A user might rely on Prometheus for metrics, Jaeger for traces, and Loki for logs. With the data lake, all telemetry data is combined without the need to reconfigure and manage the data feeds separately. The data resides in the backend together so that when users run queries or use dashboards, the user accesses the traces, logs, and metrics together. The Pod_Name = ‘XX’ is the same across all three streams, so users can more directly get to the root cause when troubleshooting versus combining the telemetry data using three different SQL queries.
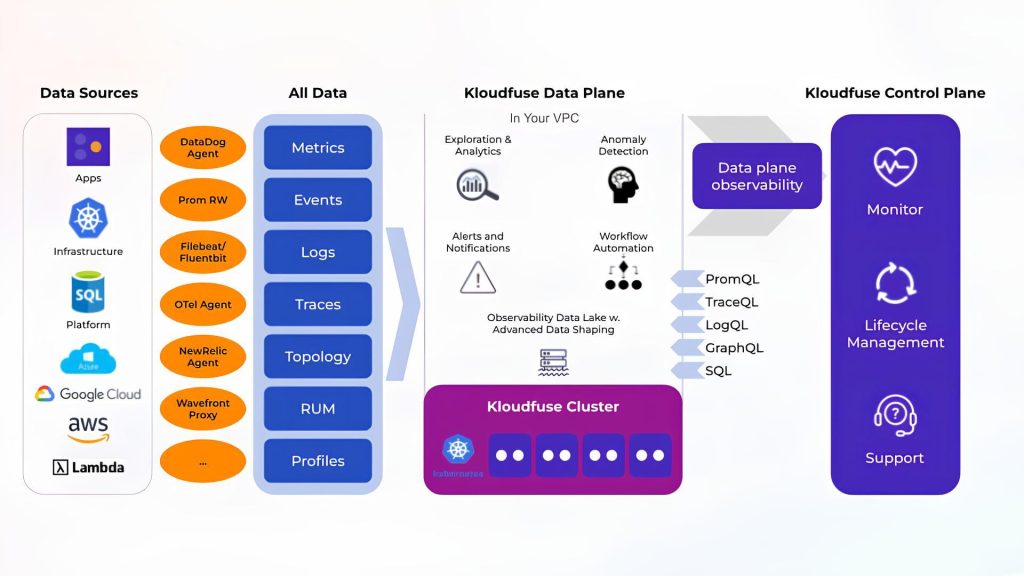
For decades, organizations that have invested in instrumentation do not want to re-instrument their applications and infrastructure. This is why a data lake must be able to accommodate data of all types without a predefined structure. “Observability data lake shouldn’t need any re-instrumentation. It’s a huge effort to ask for that,’ said Pankaj Thakkar, co-founder and CEO Kloudfuse. “Instead, the data lake should be open and able to read from all existing agents, whether it’s a Datadog agent, New Relic agent, or an OpenTelemetry agent.’”
Data does not have to be structured or parsed before ingestion — Grok scripts are not required, and there is no need to spend hours preprocessing (or tagging) your data before it can be used for observability. Theoretically, any data type can be channeled to and stored in a data lake. Users should be able to point their collector to the data lake, where it is parsed and integrated. Integrating all observability streams involves unifying telemetry data to map and link relevant data sets together. All telemetry data is in one data lake with open query language and one consistent UI for faster correlations and troubleshooting.
As Gartner analysts Miraz and Edjlali write, a data lake’s massive source data repository supports broad, flexible, and unbiased data exploration, a prerequisite for data mining, statistics, ML, and other analytics techniques. A data lake can also provide scalable and high-performance data acquisition, preparation, and processing, either to be refined and loaded into a data warehouse or for processing within the data lake, Miraz and Edjlali write.
Conversely, organizations that rely on multiple tools for monitoring and observability of one part of their stack without a data lake require multiple backends to manage metrics, traces, and logs without a data lake, creating more engineering overhead. The analytics of different streams must be manually integrated, involving slower troubleshooting processes and additional engineering costs.
Silo Removal
A data lake removes data silos. Without data silos, relationships between entities are created, such as traces, logs, metrics, and more. Users can ask any question about interdependencies in their distributed system. They can quickly drill from user sessions (RUM/front-end observability) to services to metrics and then pivot to logs, all while maintaining context so users can gain insights much faster during troubleshooting.
Data Lakes Are Cheaper
Observability Data Lakes deployed on-premises can offer demonstrable cost savings as the data in the data lake expands. This is because customers can control the analysis needed for root cause discovery of issues vs. the cost they want to pay for those insights. They get fixed costs (vs. per usage/calls they make to the vendor). There are no overages. For example, there are no egress fees to transfer the data across the network to an observability SaaS vendor.
This level of control is critical for cost constraints since each analysis and query is costly, especially with a pay-for-usage and a SaaS platform like DataDog. Many organizations trim their data before it is sent to Datadog for Observability. Logs and Traces can account for many data, often called high cardinality data.
“An in-house data lake allows you to dynamically choose when to perform in-depth analyses using extensive data—such as during troubleshooting—and when to rely on aggregated data to minimize compute and storage costs. This approach also enables you to take advantage of cloud discounts offered by providers such as AWS or GCP,” said Ashish Hanwadikar, Co-Founder & CTO of Kloudfuse.
More Than Cheap Storage
Unlike proprietary observability solutions, observability with a data lake allows data storage to be handled by low-cost object story Amazon S3 to save on storage costs. It can scale as the volumes grow without paying extra expenses. There is no single point of failure; for example, when files are configured for replication, and a node goes down, the cluster is able to continue processing queries. For horizontal scalability, a cluster can be scaled by adding new nodes when the workload increases.
Data Lakehouse Fun
For Observability, real-time analysis and anomaly detection are absolutely crucial. When data deviates from established patterns, it is essential to identify these discrepancies promptly to ensure proactive responses.
Observability data lakes offer a unified storage platform for diverse data types and powerful data processing and analytics capabilities to accelerate retrieval speeds and query performance.
This is a concept known as Data Lakehouse, where the flexibility of ingesting and storing diverse data sets, which results in quick loading speeds, is combined with the fast query response times plus efficient processing and analysis, typical of structured data organization found in traditional data warehouses. However, unlike conventional warehouses, Data Lakehouses are adaptable to a broader spectrum of data formats while delivering large-scale analytics and query performance.
A real-time OLAP design (closer to a lakehouse concept) can enable real-time analytics, monitoring, and alerting. A real-time data lakehouse can handle large volumes of data and many concurrent queries with very low query latencies. Queries can be ultra-low-latency, high query concurrency, or high data freshness (streaming data available for query immediately upon ingestion).
Not ‘Off the Shelf’
A data lake for observability consists of a centralized repository for telemetry data correlations that an observability provider should offer. Integrating other public or private data sources to create AI agents tailored to specific use cases, such as root-cause analysis and troubleshooting, predictions, infrastructure as code support, and suggestions from Copilot, Cursor, etc., are also required. However, an off-the-shelf OLAP or a data lake that does not fit this criteria cannot accurately be described as an observability data lake. While data lakes can foster real-time processing and help meet scaling needs, they lack observability capabilities since they do not have built-in IP to make them purpose-built for this use case.
Schemaless ingest and real-time analytics must be provided. So, while an OLAP or a data lake alone can serve as a solid starting point, they are not observability data lakes without schemaless ingest from open source or vendor-specific telemetry agents to make data readily available for real-time monitoring and alerting, as needed in observability use cases.
In addition to ingesting data in real time without preprocessing, observability data lakes are required to support fast query performance and ultra-low query latencies. This is critical for high-query concurrency workloads for root-cause analysis and troubleshooting modes. Proper observability data lakes should provide developed indexes for queries and analysis.
Additionally, to manage the storage and high-cardinality and dimensional telemetry data, observability data lakes should provide decoupling of storage and compute, as well as aggregations, deduplication, and compression techniques to ensure that the observability data volumes are properly stored.
Workflows and AI-Assisted Troubleshoot
A data lake deployed in VPC is instrumental in achieving data security, privacy, security, and residency. These secure data lakes are perfect for agentic workflows to enable AI-assisted troubleshooting. Agentic-AI troubleshooting apps can be built that generate and execute queries without any data leaving the organization’s boundaries, ensuring complete data privacy and compliance.
Organizations are also not required to pull the data out of expensive proprietary observability data to build these workflows. Imagine paying to get data out of DataDog (and paying the costs for it) to make your custom agent workflow that integrates observability data with other sources to create a custom workflow. Thirdly, AI agents rely on large, high-quality datasets to be effective, and a data lake provides precisely that.
LLM Observability for All
Data lakes are critical to LLM observability for two reasons: With aRAG architecture, LLM applications are composed of many/chains of calls, some to LLM models, some to external functions, databases, knowledge bases, etc., connecting all these pieces at the data layer requires an intense backend data lake. Similar to conventional observability, these calls are tracked through traces and spans, identifying the latency and performance of the different calls and relating failures to other telemetry data such as logs and accurate user monitoring. A data lake can relate all these data sets together for full context and troubleshooting.
Additionally, many calls are made to augment the LLM responses for accuracy or domain knowledge that a general-purpose LLM does not offer. With LLM observability, the user can constantly and directly evaluate the model’s and RAG’s quality and reliability since using the data in the data lake to which only the organization should have access — which is not necessarily the case without a data lake. When adding data to fine-tune an LLM application, the organization does not want to send the evaluation of the model outside of the organization’s zero trust security layer.
More Than Observability
Data lakes have emerged as a crucial way to improve observability by using a single repository for telemetry data. The emergence of AI and LLMs further expands and enhances observability’s reach and power. As organizations realize this, a growing chasm exists between those who can achieve high-powered observability with the right tools and platforms with data lakes and those who cannot. AI, LLMs, and database technologies and their application to observability will also continue to evolve. The impact will make data lakes even more of a necessity for organizations to achieve their operations and business goals.
The post Observability Without a Data Lake Might No Longer Work appeared first on The New Stack.