
For the first time in history, Amazon Web Services, Google and Microsoft have collaborated on an open source project that aims to simplify deploying and managing workloads on Kubernetes.
Kube Resource Orchestrator, Kro (pronounced “crow”), is the latest attempt to tackle the increasing complexity of Kubernetes. While there have been many attempts to accomplish this goal, Kro stands out for its simplicity and easy-to-adopt approach.
This series has two parts. In the first part, I will discuss the motivation behind Kro, the architecture, the use cases and how it differs from tools such as Helm and Kustomize. In the second part, which we will post next Friday, I will walk you through a hands-on tutorial on deploying a cloud native workload through Kro.
The Complexity of Dealing With Kubernetes
Although Kubernetes is in its 11th year, developers, operators and SREs still consider it complex. Installing, managing, scaling and handling Kubernetes requires advanced skills and a thorough understanding of its underpinnings. Numerous attempts have been made to address this problem. Helm was introduced as a package manager, and Cloud Native Application Bundles (CNAB) was created as a standardized packaging format for distributed applications.
Microsoft and Alibaba collaborated to create the Open Application Model, which eventually took the shape of KubeVela. However, application developers must still deal with a fragmented set of Kubernetes resources to deploy an application.
Take WordPress, for example. It needs a configmap to store WordPress configuration files, secrets to store credentials of MySQL, a persistent volume and a claim for storage, a statefulset to run MySQL in HA, services to expose MySQL and WordPress, and finally, an ingress resource to expose the endpoint to the outside world. This leaves a lot to the operators when planning a deployment.
While a single Helm Chart may come to the rescue, it’s primarily a design time packaging format. Once a workload is deployed, managing individual parts is still left to DevOps.
What Is Kro?
Kro is a Kubernetes native framework that simplifies the creation of complex Kubernetes resource configurations. Instead of managing individual resources, both during the definition and at runtime, Kro allows operators to group them into reusable units, making deployments more efficient and manageable.
Kro introduces the concept of a ResourceGraphDefinition (RGD). This Kubernetes custom-resource definition declares a collection of underlying Kubernetes resources and their relationships. It is a blueprint for creating and managing these resources as a single unit. The name change to ResourceGraphDefinition better reflects its purpose and avoids ambiguity.
Kro utilizes the Common Expression Language (CEL), also employed by Kubernetes webhooks, for its logical operations. With CEL expressions, Kubernetes users can seamlessly transfer values between objects and integrate conditionals into custom API definitions. Based on these expressions, Kro automatically determines the correct sequence for object creation.
Think of an RGD as an aggregated YAML file that contains every Kubernetes resource needed by the workload. But it is more than just the aggregation. An RGD, as the name suggests, is a Direct Acyclic Graph (DAG) for your application. It is intelligent enough to understand the dependencies and deployment sequence of the resources. The RGD is a Custom Resource Definition (CRD) and a controller that can manage the entire definition as an atomic unit.
A ResourceGraphDefinition consists of a schema and resources section. The schema defines the API structure, including the fields users can configure and status information. The resources section specifies the Kubernetes resources to create, their templates, dependencies, conditions for inclusion and readiness criteria.
When you define an RGD, you indirectly create a CRD for your custom application. From this CRD, you can create multiple instances of your application.
Below is an example of a simple web application based on an Apache web server packaged as a Kubernetes deployment and service.
apiVersion: apps/v1
kind: Deployment
metadata:
name: web-app
spec:
replicas: 1
selector:
matchLabels:
app: apache
template:
metadata:
labels:
app: apache
spec:
containers:
- name: apache
image: httpd:latest
ports:
- containerPort: 80
apiVersion: v1
kind: Service
metadata:
name: apache-service
spec:
type: NodePort
selector:
app: apache
ports:
- protocol: TCP
port: 80
targetPort: 80
nodePort: 30080
Converting this into an RDG is straightforward. We will merge these two definitions (deployment and service) into a single resource graph.
apiVersion: kro.run/v1alpha1
kind: ResourceGraphDefinition
metadata:
name: web-app
spec:
schema:
apiVersion: v1alpha1
kind: Application
spec:
name: string
image: string | default="httpd:latest"
replicas: integer | default=1
svcType: string | default="ClusterIP"
status:
deploymentConditions: ${deployment.status.conditions}
availableReplicas: ${deployment.status.availableReplicas}
resources:
- id: deployment
template:
apiVersion: apps/v1
kind: Deployment
metadata:
name: ${schema.spec.name}
spec:
replicas: ${schema.spec.replicas}
selector:
matchLabels:
app: ${schema.spec.name}
template:
metadata:
labels:
app: ${schema.spec.name}
spec:
containers:
- name: ${schema.spec.name}
image: ${schema.spec.image}
ports:
- containerPort: 80
- id: service
template:
apiVersion: v1
kind: Service
metadata:
name: ${schema.spec.name}-service
spec:
type: ${schema.spec.svcType}
selector: ${deployment.spec.selector.matchLabels}
ports:
- protocol: TCP
port: 80
targetPort: 80
The above RGD turned our deployment into a parameterized resource graph. Notice how the deployment and service names are inherited from the application name. Similarly, we made the image of the deployment and the port used for the service as parameters that can be defined during the deployment phase.
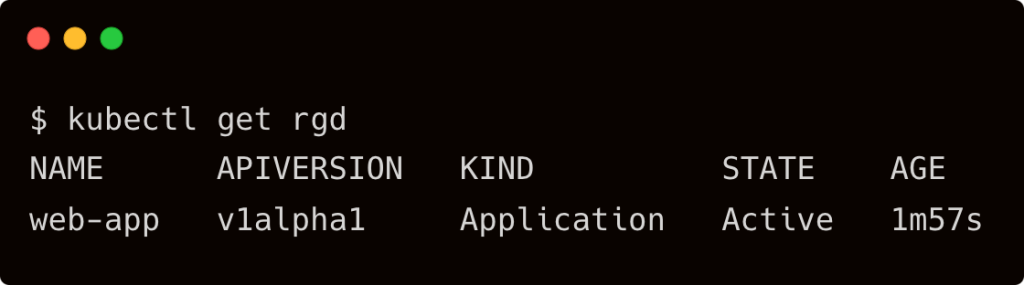
Once the RGD is defined, we can create multiple instances of this by declaring the application. Below is an example of this:
apiVersion: kro.run/v1alpha1 kind: Application metadata: name: web-app-1 spec: name: web-app-1 image: "httpd:2.4" replicas: 3 svcType: "NodePort"
We will create another instance while leveraging the same resource graph by changing the image to Nginx instead of Apache.
apiVersion: kro.run/v1alpha1 kind: Application metadata: name: web-app-2 spec: name: web-app-2 image: "nginx"
Now, we have two applications that are running in our cluster.
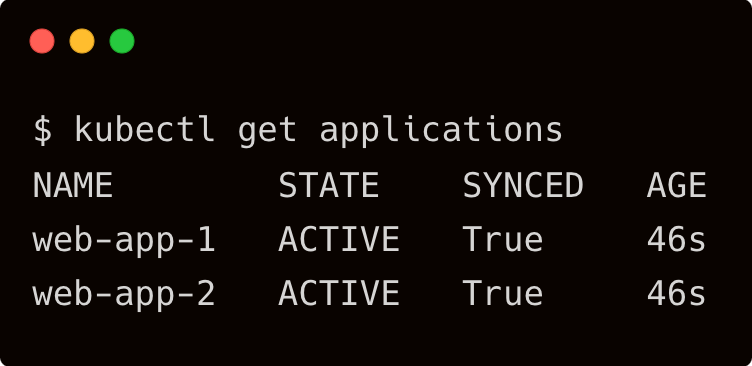
It’s important to understand that Kubernetes has no special knowledge of these applications. It simply deconstructs the definition and deploys individual resources in a normal mode.
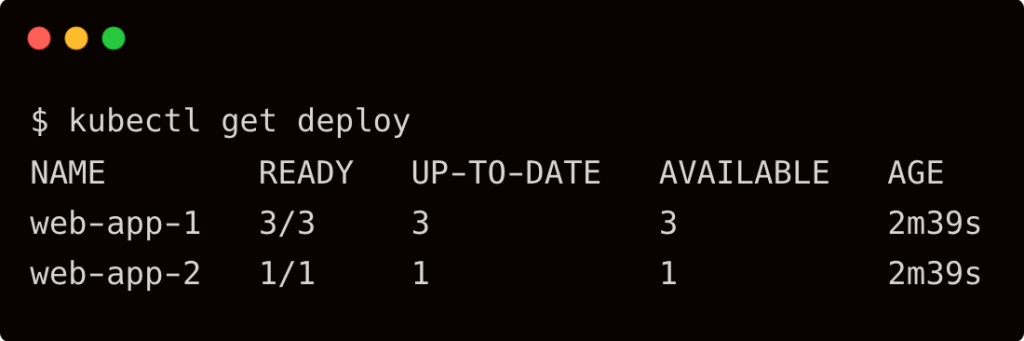
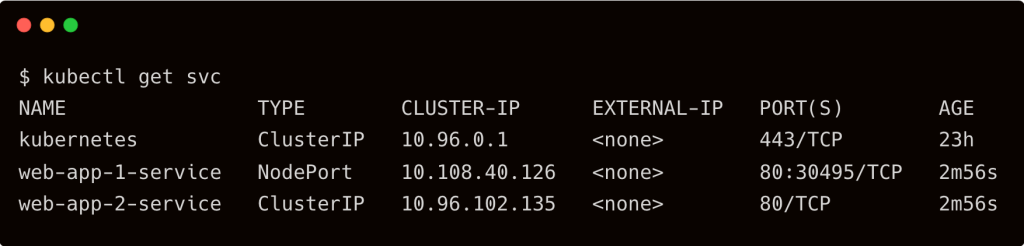
Since Kro gives us an application-level primitive, we can now modify and apply the instance to make changes. For example, I want to modify the service type of the application, web-app-2, which is currently a ClusterIP, to a NodePort and also increase the replicas to 6.
apiVersion: kro.run/v1alpha1 kind: Application metadata: name: web-app-2 spec: name: web-app-2 image: "nginx" replicas: 6 svcType: "NodePort"
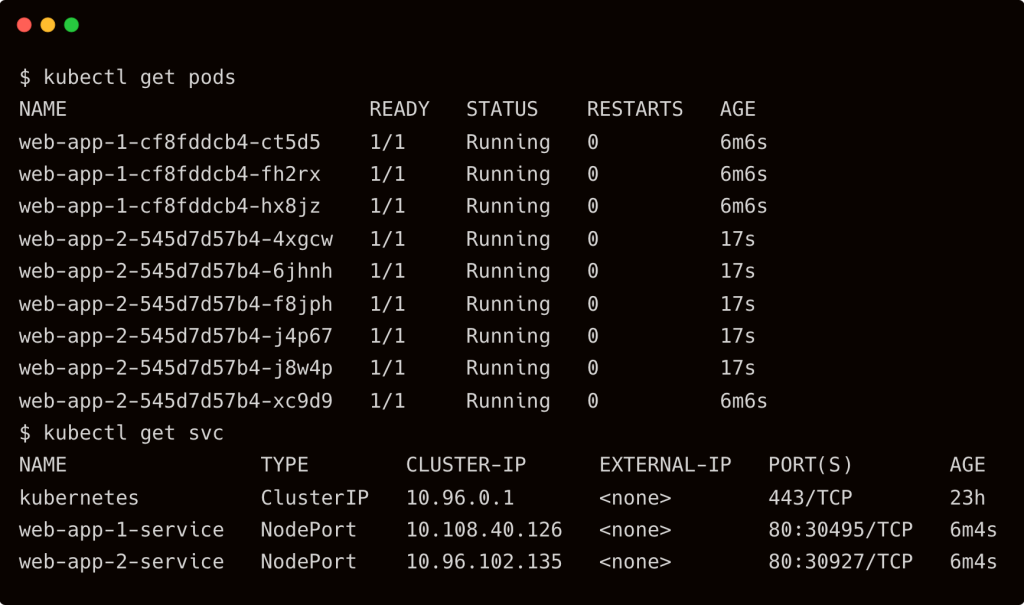
Notice that the service for web-app-2 has changed from ClusterIP to NodePort, and the deployment scaling out to 6 replicas.
Hopefully, this gives you an idea of what Kro can accomplish and its power in managing a set of Kubernetes resources as a logical unit.
Kro brings powerful platform engineering capabilities to enterprises. Central IT teams can define RDG that imposes the proper governance, policies and compliance measures and that lets individual teams modify what is essential for their workloads. This not only enforces policies but also hides the complexity of Kubernetes by abstracting the primitives from the DevOps teams.
Kro vs. Helm and Kustomize
While Kro shares some similarities with Helm and Kustomize, the objective differs. Let’s compare and contrast Kro with these two popular tools.
Kro’s structured YAML with CEL offers a more secure and predictable runtime than Helm’s Turing-complete templating language. CEL’s use also ensures a predictable computational cost, as the API server handles the execution. Kro’s automatic dependency management based on a DAG ensures proper deployment ordering. While Helm charts are packaged and distributed, Kro relies on ResourceGraphDefinitions applied to the cluster. Kro also handles CRD upgrades better than Helm, making it easier to manage updates and avoid potential issues.
Compared to Kustomize, Kro offers more advanced features, such as automatic dependency management and the ability to create custom resources and controllers. Kustomize focuses on customizing existing manifests, while Kro provides a more comprehensive solution for resource orchestration. Some users believe that Kro has the potential to become the preferred tool for managing Kubernetes deployments, potentially replacing Helm in the future.
Kro is a powerful tool that simplifies Kubernetes resource management by allowing you to define and manage complex resource configurations as reusable components. With the collaborative efforts of AWS, Google Cloud and Microsoft, Kro is poised to become a key player in the Kubernetes ecosystem, making the platform more accessible and efficient for everyone. As Kro continues to evolve, it promises to streamline Kubernetes deployments further and empower developers to build and deploy applications with greater ease and confidence.
In the next part of this series, I will walk you through all the steps involved in deploying an advanced cloud native workload through Kro. Stay tuned.
The post Kubernetes Gets a New Resource Orchestrator in the Form of Kro appeared first on The New Stack.
Comments are closed.