
Before 2020, the word “cottagecore” pretty much didn’t exist. But the Covid pandemic spurred a lot of people looking into making their own homes a lot more comfy, and generally romanticizing a simpler, more rustic life. The term thrived online, conjuring images of picnic baskets of dried flowers, cast-iron stoves, bowls full of fruit and the like.
For the managers of Canva, the graphic design platform, keeping up with such linguistic trends is essential to serving its user base. Trends breed business, and businesses need promotion. And as soon as a new term like cottagecore comes about, graphic designers, marketing folks and millions of other monthly users will be looking to Canva for the perfect image to grace their web, marketing and promotional materials.
So how does Canva identify which images would fit into a new category such as cottagecore? It manages a library of over 40 billion images — either from stock photo services or shared by its users — and it ingests between 50 to 100 million new images each day.
Clearly, marking them images by hand would not scale.
“We need accurate real-time labeling at scale,” explained Kerry Halupka, Canva principal machine learning engineer, during a talk given for ScyllaDB‘s Monster Scale Summit 2025, held virtually last week.
And this classification system can be tricker than one might initially imagine.
Beyond the Literal
Take, as an example, a photograph of a father, still in his business suit, playing with what appears to be his young son in a living room, with kid toys scattered about the floor.
Image-to-text services can easily identify all the objects in the photograph. But the photo could also be identified under more abstract categories, such as “work-life balance,” or “father-son bonding” or even, ironically, “professional parent.”
The challenge is that none of those concepts can be identified within the photo itself.
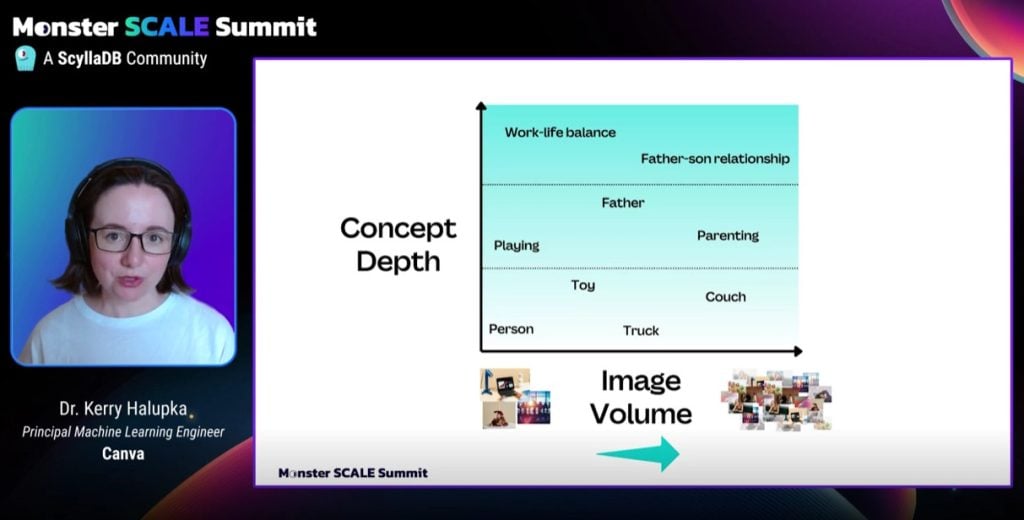
“It’s not just about identifying objects, but it’s about understanding context and meaning,” Halupka said.
And these terms aren’t static. New concepts are surfacing every day. And this is a problem that any industry — not just graphic design — faces when trying to use AI for any sort of classification work.
“Concepts that are important to users aren’t static,” Halupka explained. “It’s a moving target, with new trends popping up every day. So we needed a model that could handle thousands of labels and easily expand to thousands more to capture these deeper concepts.
“Our goal is to push machines beyond identifying simple objects and closer to a nuanced understanding of a human,” Halupka said.
And, given the size of Canva’s image bank, a classification system would have to be fast. Overly complicated models would be too costly to maintain. And it had to be fast, so it could pick up new trends as the users themselves are picking up on them.
An “Extreme Classification System”
To hit these goals, the team looked outside of the typical machine learning transformer-decoder architectures. Traditional classification architectures scale “worse than linearly,” with the number of labels to classify, Halupka said.
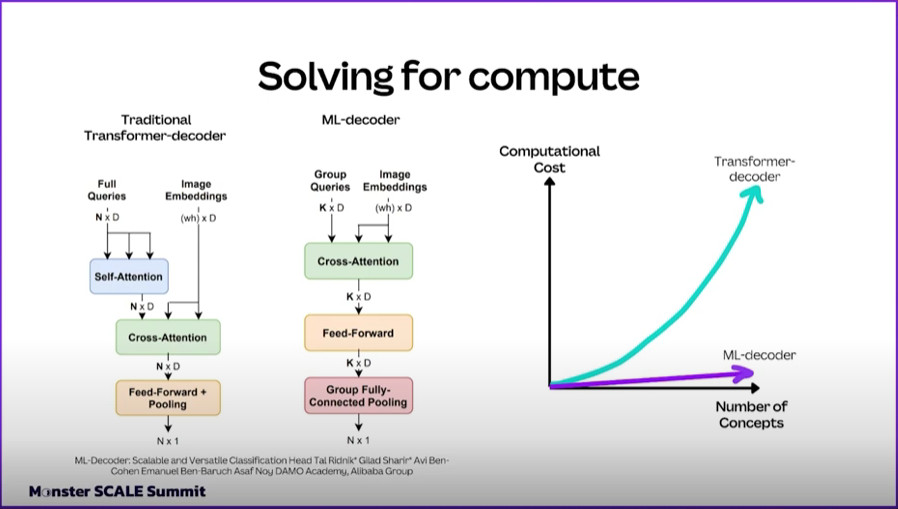
Instead, it landed on the ML-Decoder architecture, which originated from Alibaba and the DAMO Academy. The development team found that ML-Decoder scales “better than linearly” with the number of concepts introduced into the system, Halupka explained.
“ML-Decoder predicts the existence of class labels via queries, and enables better utilization of spatial data compared to global average pooling. By redesigning the decoder architecture, and using a novel group-decoding scheme, ML-Decoder is highly efficient, and can scale well to thousands of classes,” the originators of ML-Decoder explain in a paper.
An Interactive Data Labeling Pipeline
Training to an entirely new term — such as cottagecore — required training samples, and preferably without labeling thousands of images by hand beforehand.
So the company built an interactive data labeling pipeline to define new concepts. Once a new concept is identified (“cottagecore”), the pipeline finds images that are close matches using a combination of text-based and image-based search on a small training set. Then the entire image bank is checked. In many cases, previously unlabeled images will get tagged with the new term. And in other cases, already-labeled images will also be a fit for the new term.
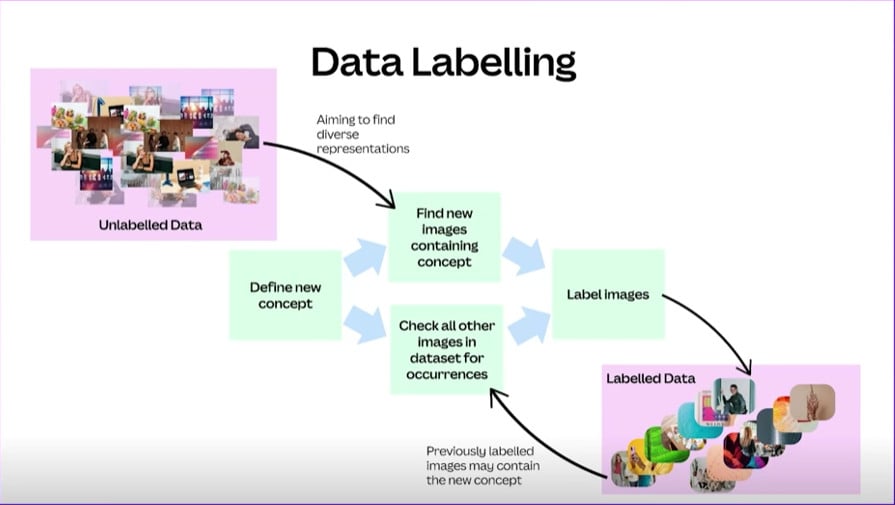
“It’s a feedback loop. Each new concept expands our ability to classify images more accurately over time,” Kerry Halupka explained.
To help contextualize a single search term, Canva uses a large language model to generate more verbose descriptions from a single phrase.
‘Cottagecore,” for instance could spawn:
- “A cozy farmhouse kitchen”
- “A young woman with wildflowers”
- “A picnic in the woods”
Though less obvious, these are all the kinds of images one would still expect to see with the “cottagecore” label, Halupka said.
To find images that meet these more verbose descriptions, Canva uses CLIP (Contrastive Language-Image Pretraining), a Python-based neural network trained on finding image/text pairings in a shared space.
“As CLIP understands concepts more naturally than traditional keyword matching, it can find examples even when they’re not explicitly labeled,” Halupka explained.
So a phrase such as “cozy cottage kitchen, with vintage decor,” may turn up images that meet this description but previously were not marked as “cottagecore,” but do match that aesthetic through the most closely matching vectors.
When new labels are introduced into the model, they are still rated as “low confidence,” so they then can be inspected by the VisualCritic LLM to further validate the label.
“The outcome is a continuously improving training set that keeps up to date with evolving content and vocabulary and can be used to train small, efficient models that can run at large scale,” Halupka said.
“The power of this approach is that it’s both scalable and maintainable. When we need to add new concepts, whether it’s cottagecore today or whatever trend emerges tomorrow, this automated pipeline can find diverse, accurately labeled examples without massive manual effort. Because each step is optimized for quality. We can maintain high accuracy, even at massive scale.”
View the entire presentation here:
The post How Canva Keeps Its Image Metadata Fresh appeared first on The New Stack.