
For several years now, we’ve taken for granted that many transformer-based large language models (LLMs) use a technique known as autoregression. This machine learning technique aligns well with how many languages work, in that it processes and generates each word, or token, sequentially from left to right. But with the increasing complexity of AI-generated text, the costs of inference and problems with latency have risen as well.
However, there may be a better way, thanks to the recent release of Mercury by US-based Inception Labs, the first commercial-scale diffusion large language model (dLLM) that promises faster and more efficient text generation, using the same diffusion-based approach that underpins image generation models like DALL-E, Stable Diffusion, and Midjourney.
Autoregression vs. Diffusion
Conventional autoregressive-based large language models will process tokens consecutively, with the generation of each new word being dependent on the previous tokens of the sequence. There are notable advantages to this approach: it offers more coherence, contextual depth, and realistic outputs that capture the dependencies between words and phrases. However, the drawbacks to these models include increased computational cost, slower inference speed, and more potential errors.
In contrast, the non-sequential nature of diffusion models overcomes many of these issues. For generating images, diffusion models work by first progressively adding random noise to an image in a process called “noising”. The model then learns to revert back from this added noise, by iteratively “de-noising” to reconstruct the original image. Through these processes, the model learns to recognize patterns, and ultimately how to synthesize and continuously refine similar images in the future.

How diffusion models work for image generation — noising and de-noising. Via Tim Cvetko.
This holistic, parallelized approach of diffusion models is incredibly effective with generating images and video, but has been difficult to achieve with text — until now.
“Transformers dominate LLM text generation and create tokens sequentially. Diffusion models offer an alternative — they generate all the text simultaneously, applying a coarse-to-fine process,” explained DeepLearning.ai founder Andrew Ng in a post on X.
Mercury Accelerates Language Generation
According to the company, Mercury is five times faster than conventional large language models and up to 10 times faster than other speed-optimized LLMs — plus, overall, it is cheaper to run. Mercury models can operate at over 1,000 tokens per second on NVIDIA H100s — a blazing-fast speed that was previously attainable only with custom chips from specialized hardware companies like Groq, Cerebras, and SambaNova.
Currently, it’s available as a demo as Mercury Coder, a diffusion large language model that is specifically optimized for generating code. You can see how it stacks up to other LLMs in real-time code generation in the video below.
According to Inception Labs, the “small” version of Mercury Coder is on par with OpenAI’s GPT-4o Mini and Claude 3.5 Haiku, while performing 10 times as fast during testing. The “mini” Mercury model outperforms small open source models like Meta’s Llama 3.1 8B, achieving more than 1,000 tokens per second. Compared to some frontier LLMs that run at less than 50 tokens per second, Mercury offers a 20X speedup.

Speed comparison: output tokens per second, coding workload. Via Inception Labs.
When evaluated on standard coding benchmarks, Mercury Coder is able to either hold its own or surpass its competitors, while maintaining a high level of quality in its outputs.
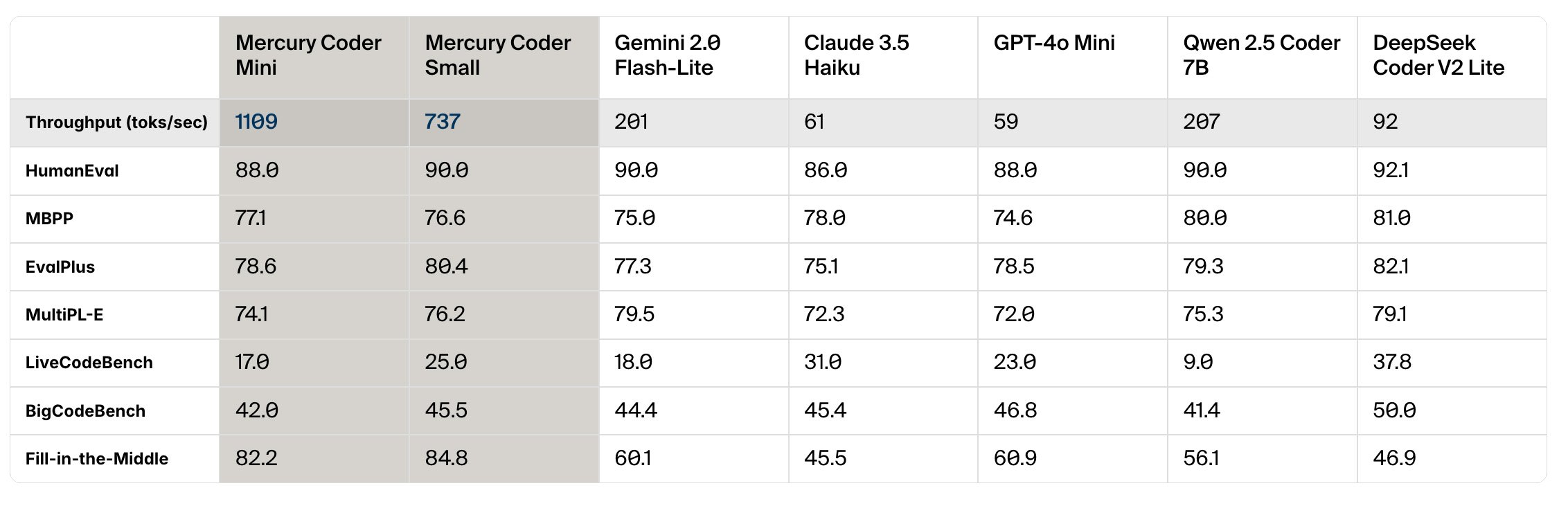
Via Inception Labs.
Potential Impacts on AI
With Mercury leveraging commodity GPUs much more effectively, this could mean decreased cost of inference, without too much of a negative impact on performance and without the need for specialized hardware. This could mean even more enhanced performance for diffusion models like Mercury in the future, as GPUs continue to evolve.
Currently, there are some downsides when it comes to diffusion models. Whereas autoregressive models only need one pass per token, diffusion models usually require tokens to go through several forward passes on the neural network before it can generate an output. However, this potential disadvantage is mostly balanced out by the fact that diffusion models can process all tokens simultaneously in a parallel way.
Potential Uses for Diffusion-Based Text Generation
Inception Labs believes that diffusion-based text generation would be an excellent fit for code generation, enterprise automation, as well as latency-sensitive use cases like conversational AI, agentic AI and in resource-constrained situations (such as mobile devices). Due to dLLMs’ advanced reasoning capabilities, they can correct hallucinations, while still processing answers — all in the space of seconds. In the long run, models like Mercury could signal a paradigm shift from autoregressive to diffusion-based models for quick and efficient text generation.
Mercury is now available as a coding demo, and also to enterprise customers via an API and deployments on-premise, with fine-tuning support being offered for both. To find out more, visit Inception Labs.
The post Get Ready for Faster Text Generation With Diffusion LLMs appeared first on The New Stack.



