Introduction
As AI adoption continues to grow, organizations are increasingly faced with the challenge of efficiently deploying, managing, and scaling their models in production. The complexity of modern AI systems demands robust strategies that address the entire lifecycle — from initial deployment to rollback mechanisms, cloud migration, and proactive issue management.
A critical element in achieving stability is AI observability, which empowers teams to track key metrics such as latency, memory usage, and performance degradation. By leveraging tools like Prometheus, Grafana, and OpenTelemetry, teams can gain actionable insights that drive informed rollback decisions, optimize scaling, and maintain overall system health.
This blog explores a comprehensive strategy for ensuring seamless AI deployment while enhancing system stability and performance.
AI-Powered Full Lifecycle Workflow
Managing the complete lifecycle of AI models requires proactive monitoring, intelligent rollback mechanisms, and automated recovery strategies. Below is an improved AI-powered workflow that integrates these elements.
AI-Powered Lifecycle Workflow with Rollback Integration
To ensure seamless AI deployment and minimize downtime, integrating a proactive rollback decision strategy within the AI lifecycle is crucial. The following diagram illustrates the complete AI deployment workflow with integrated rollback and fallback mechanisms to ensure high availability and performance stability.
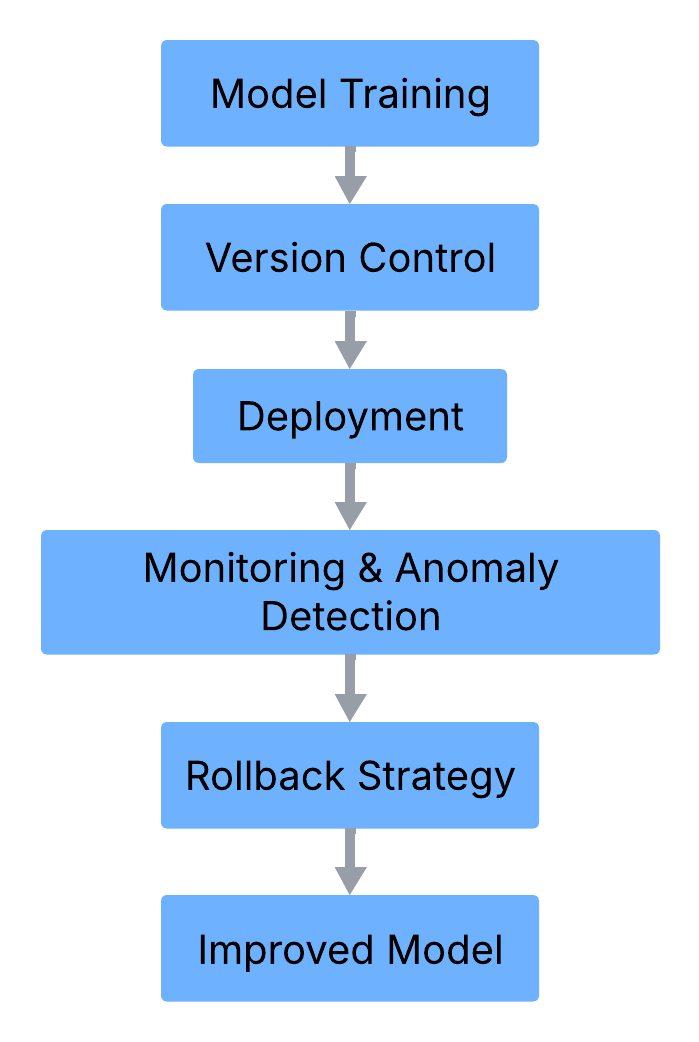
This diagram visualizes the AI deployment lifecycle, integrating steps such as training model, version control, deployment, and rollback strategies to ensure model performance and system stability.
-
Model Training and Versioning:
- Use MLflow or DVC for model version control.
- Implement automated evaluation metrics to validate model performance before deployment.
-
Automated Deployment with Rollback Support:
- Implement Kubernetes ArgoCD or FluxCD for automated deployments.
- Trigger rollback automatically when degradation is detected in latency, accuracy, or throughput.
-
Proactive Monitoring and Anomaly Detection:
- Use tools like Prometheus, Grafana, or OpenTelemetry to monitor system metrics.
- Integrate AI-driven anomaly detection tools like Amazon Lookout for Metrics or Azure Anomaly Detector to proactively detect unusual patterns and predict potential failures.
-
Intelligent Rollback Strategy:
- Use AI logic to predict potential model failure based on historical trends.
- Develop fallback logic to dynamically revert to a stable model version when conditions deteriorate.
-
Continuous Improvement Pipeline:
- Integrate Active Learning pipelines to improve model performance post-deployment by ingesting new data and retraining automatically.
Example Code for AI-Driven Rollback Automation
import mlflow
import time
import requests
# Monitor endpoint for AI model performance
def check_model_performance(endpoint):
response = requests.get(f"{endpoint}/metrics")
metrics = response.json()
return metrics['accuracy'] # Extract accuracy for performance check
# Rollback logic with AI integration
def intelligent_rollback():
# Get the current model version
current_version = mlflow.get_latest_versions("my_model")
# Check the current model's performance metrics
current_accuracy = check_model_performance("http://my-model-endpoint")
# Rollback condition if performance deteriorates
if current_accuracy < 0.85:
print("Degradation detected. Initiating rollback.")
previous_version = mlflow.get_model_version("my_model", stage="Production", name="previous")
mlflow.register_model(previous_version)
else:
print("Model performance is stable.")
# Periodic check and rollback automation
while True:
intelligent_rollback() # Run rollback logic every 5 minutes
time.sleep(300)
AI Model Types and Their Deployment Considerations
Understanding the characteristics of different AI models is crucial to developing effective deployment strategies. Below are some common model types and their unique challenges:
1. Generative AI Models
- Examples: GPT models, DALL-E, Stable Diffusion.
- Deployment Challenges: Requires high GPU/TPU resources, is sensitive to latency, and often involves complex prompt tuning.
-
Best Practices:
- Implement GPU node pools for efficient scaling.
- Use model pre-warming strategies to reduce cold start delays.
- Adopt Prompt Engineering Techniques:
- Prompt Templates: Standardize prompt structures to improve inference stability.
- Token Limiting: Limit prompt size to prevent excessive resource consumption.
- Use prompt tuning libraries like LMQL or LangChain for optimal prompt design.
2. Deep Learning Models
- Examples: CNNs (Convolutional Neural Networks), RNNs (Recurrent Neural Networks), Transformers.
- Deployment Challenges: Memory leaks in long-running processes and model performance degradation over time.
-
Best Practices:
- Adopt checkpoint-based rollback strategies.
- Implement batch processing for efficient inference.
- Use Kubernetes GPU Scheduling to assign GPU resources efficiently for large model serving.
- Leverage frameworks like NVIDIA Triton Inference Server for optimized model inference with auto-batching and performance scaling.
3. Traditional Machine Learning Models
- Examples: Decision Trees, Random Forest, XGBoost.
- Deployment Challenges: Prone to data drift and performance decay.
-
Best Practices:
- Use tools like MLflow for version tracking.
- Automate rollback triggers based on performance metrics.
- Integrate with Feature Stores such as Feast or Tecton to ensure data consistency and feature availability during deployment.
4. Reinforcement Learning Models
- Examples: Q-learning, Deep Q-Network (DQN), DDPG (Deep Deterministic Policy Gradient).
- Deployment Challenges: Continuous learning may require dynamic updates in production.
-
Best Practices:
- Use blue-green deployment strategies for smooth transitions and stability.
- Implement Checkpointing to maintain model progress during unexpected interruptions.
- Leverage frameworks like Ray RLlib to simplify large-scale RL model deployment with dynamic scaling.
Rollback Strategy for AI Models
Ensuring stable rollback processes is critical to mitigating deployment failures. Effective rollback strategies differ based on model complexity and deployment environment.
The following diagram illustrates the decision-making process for determining if an AI model rollback or fallback model deployment is necessary, ensuring stability during performance degradation.
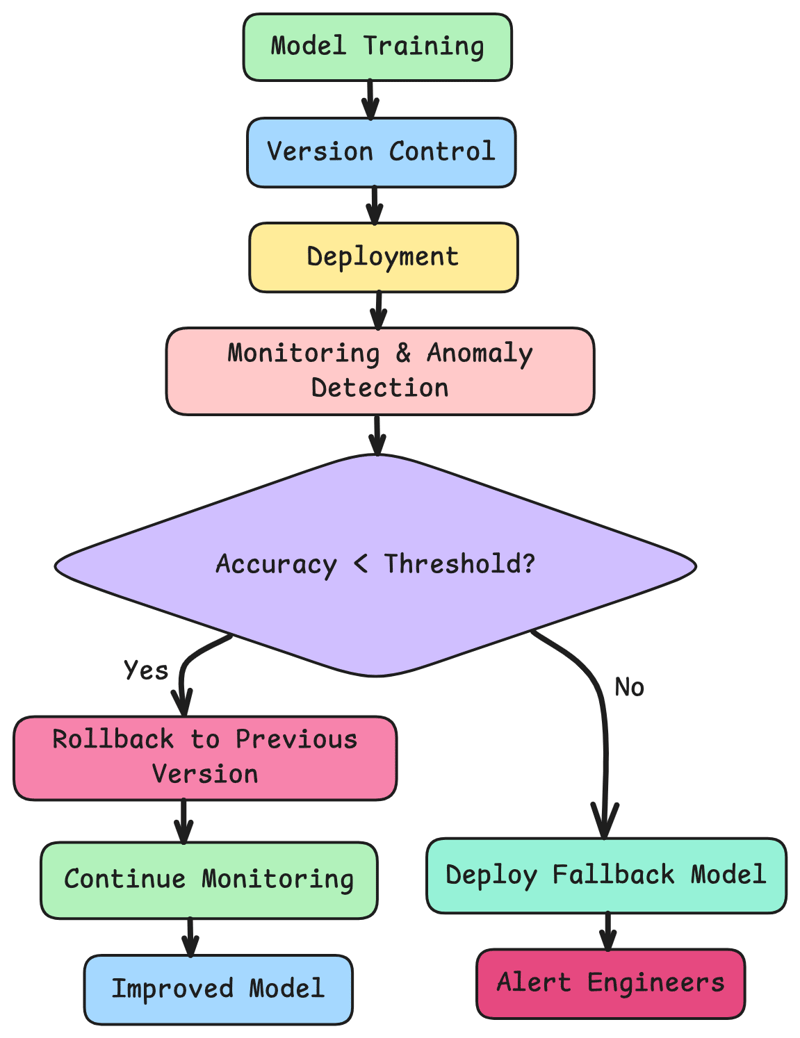
Fallback Model Concept
To reduce downtime during rollbacks, consider deploying a lightweight fallback model that can handle core logic while the primary model is restored.
Example Fallback Strategy:
- Primary Model: A Transformer-based NLP model.
- Fallback Model: A simpler logistic regression model for basic intent detection during failures.
Proactive Rollback Triggers
Implement AI-driven rollback triggers that identify performance degradation early. Tools like EvidentlyAI, NannyML, or Seldon Core can detect:
- Data Drift
- Concept Drift
- Unusual Prediction Patterns
- Spike in Response Latency
Expanded Kubernetes Rollback Example
apiVersion: apps/v1
kind: Deployment
metadata:
name: ai-model-deployment
spec:
replicas: 3
strategy:
type: RollingUpdate
rollingUpdate:
maxUnavailable: 1
maxSurge: 2
template:
metadata:
labels:
app: ai-model
spec:
containers:
- name: ai-container
image: ai-model:latest
resources:
limits:
memory: "4Gi"
cpu: "2000m"
livenessProbe:
httpGet:
path: /health
port: 8080
initialDelaySeconds: 10
periodSeconds: 5
readinessProbe:
httpGet:
path: /ready
port: 8080
initialDelaySeconds: 5
periodSeconds: 10
startupProbe:
httpGet:
path: /startup
port: 8080
failureThreshold: 30
periodSeconds: 10
Holiday Readiness for AI Systems
During peak seasons or high-traffic events, AI deployments must be robust against potential bottlenecks. To ensure system resilience, consider the following strategies:
1. Load Testing for Peak Traffic
Simulate anticipated traffic spikes with tools like:
- Locust — Python-based framework ideal for scalable load testing.
- k6 — Modern load testing tool with scripting support for dynamic scenarios.
- JMeter — Comprehensive tool for testing API performance under heavy load.
Example Locust Test for AI Endpoint Load Simulation:
from locust import HttpUser, task, between
class APITestUser(HttpUser):
wait_time = between(1, 5)
@task
def test_ai_endpoint(self):
self.client.post("/predict", json={"input": "Holiday traffic prediction"})
2. Circuit Breaker Implementation
Implement circuit breakers to prevent overloading downstream services during high load. Tools like Resilience4j or Envoy can automatically halt requests when services degrade.
Sample Resilience4j Circuit Breaker Code in Python:
from resilience4py.circuitbreaker import circuit
@circuit(failure_threshold=5, recovery_time=30)
def predict(input_data):
# AI Model Prediction Logic
return model.predict(input_data)
3. Chaos Engineering for Resilience
Conduct controlled failure tests to uncover weaknesses in AI deployment pipelines. Recommended tools include:
- Gremlin — Inject controlled failures in cloud environments.
- Chaos Mesh — Kubernetes-native chaos testing solution.
- LitmusChaos — Open-source platform for chaos engineering in cloud-native environments.
Example: Running a Pod Failure Test with Chaos Mesh
apiVersion: chaos-mesh.org/v1alpha1
kind: PodChaos
metadata:
name: pod-failure-example
spec:
action: pod-kill
mode: one
selector:
namespaces:
- default
4. Caching Strategies for Improved Latency
Caching plays a crucial role in reducing latency during peak loads. Consider:
- Redis for fast, in-memory data storage.
- Cloudflare CDN for content caching at the edge.
- Varnish for high-performance HTTP caching.
Example Redis Caching Strategy in Python:
import redis
cache = redis.Redis(host='localhost', port=6379, db=0)
def get_prediction(input_data):
cache_key = f"prediction:{input_data}"
if cache.exists(cache_key):
return cache.get(cache_key)
else:
prediction = model.predict(input_data)
cache.setex(cache_key, 3600, prediction) # Cache for 1 hour
return prediction
Cloud Migration Strategies for AI Models
Moving AI models to the cloud requires careful planning to ensure minimal downtime, data integrity, and secure transitions. Consider the following strategies for a smooth migration:
1. Data Synchronization for Seamless Migration
Ensure smooth data synchronization between your current infrastructure and the cloud.
- Rclone — Efficient data transfer tool for cloud storage synchronization.
- AWS DataSync — Automates data movement between on-premises storage and AWS.
- Azure Data Factory — Ideal for batch data migration during AI pipeline transitions.
Example Rclone Synchronization Command:
rclone sync /local/data remote:bucket-name/data –progress
2. Hybrid Cloud Strategy
A hybrid cloud strategy helps manage active workloads across multiple environments. Tools like:
- Anthos — Manages Kubernetes clusters across Google Cloud and on-prem.
- Azure Arc — Extends Azure services to on-prem and edge environments.
- AWS Outposts — Deploys AWS services locally to ensure low-latency AI inference.
Example Anthos GKE Configuration for Hybrid Cloud:
apiVersion: v1
kind: Pod
metadata:
name: hybrid-cloud-ai
spec:
containers:
- name: model-inference
image: gcr.io/my-project/ai-inference-model
resources:
limits:
cpu: "2000m"
memory: "4Gi"
3. Migration Rollback Strategy
Implement a Canary Deployment strategy for cloud migration, gradually shifting traffic to the new environment while monitoring performance.
Sample Canary Deployment with Kubernetes:
apiVersion: flagger.app/v1beta1
kind: Canary
metadata:
name: ai-model
spec:
targetRef:
apiVersion: apps/v1
kind: Deployment
name: ai-model
progressDeadlineSeconds: 60
analysis:
interval: 30s
threshold: 5
metrics:
- name: success-rate
thresholdRange:
min: 95
4. Data Encryption and Security
To ensure security during data migration:
- Encrypt data in-transit using TLS.
- Encrypt data at-rest using cloud-native encryption services like AWS KMS, Azure Key Vault, or Google Cloud KMS.
- Apply IAM Policies to enforce strict access controls during data transfers.
5. Cloud-Specific AI Model Optimization
Optimize AI inference performance with cloud-specific hardware accelerators:
- Use TPUs in Google Cloud for Transformer and vision model efficiency.
- Use AWS Inferentia for cost-effective large-scale inference.
- Use Azure NC-series VMs for high-performance AI model serving.
Example: AI-Driven Cloud Migration Workflow
Using Python’s MLflow and Azure Machine Learning, the following code demonstrates how to track model versions and manage migration:
import mlflow
from azureml.core import Workspace, Model
from azureml.core.webservice import AciWebservice, Webservice
from azureml.core.model import InferenceConfig
# Load Azure ML Workspace Configuration
ws = Workspace.from_config()
# Register Model
model = mlflow.sklearn.load_model("models:/my_model/latest")
model_path = "my_model_path"
mlflow.azureml.deploy(model, workspace=ws, service_name="ai-model-service")
# Define Inference Configuration for Deployment
inference_config = InferenceConfig(
entry_script="score.py", # Python scoring script for inference
environment="env.yml" # Environment configuration file
)
# Define Deployment Configuration
deployment_config = AciWebservice.deploy_configuration(
cpu_cores=1,
memory_gb=2,
auth_enabled=True, # Enable authentication for security
tags={'AI Model': 'Cloud Migration Example'},
description='AI model deployment for cloud migration workflow'
)
# Deploy Model as a Web Service
service = Model.deploy(
workspace=ws,
name="ai-model-service",
models=[model],
inference_config=inference_config,
deployment_config=deployment_config
)
service.wait_for_deployment(show_output=True)
print(f"Service Deployed at: {service.scoring_uri}")
# Migration Strategy Function
def migration_strategy(model_version):
"""
Automated Migration Strategy:
- Checks the current model's version accuracy.
- Rolls back to the previous version if performance degrades.
"""
current_model = mlflow.get_model_version("my_model", model_version)
# Simulate performance check
model_accuracy = 0.84 # Example accuracy threshold
if model_accuracy < 0.85:
print(f"Model version {model_version} underperforming. Rolling back...")
previous_version = mlflow.get_model_version("my_model", stage="Production", name="previous")
mlflow.register_model(previous_version)
else:
print(f"Model version {model_version} performing optimally.")
# Example Usage
#migration_strategy("latest")
Recommended Cloud Tools for Migration
- Azure Migrate for step-by-step migration planning.
- AWS Application Migration Service for automating replication and failover.
- Google Cloud Migrate for ensuring data integrity during migration.
Conclusion
AI deployment demands a comprehensive strategy that combines automated lifecycle management, rollback capabilities, and effective cloud migration. By adopting specialized strategies for different model types, organizations can ensure stability, scalability, and performance even in high-pressure environments.
In this blog, we explored strategies tailored for different AI model types such as Generative AI Models, Deep Learning Models, Traditional Machine Learning Models, and Reinforcement Learning Models. Each model type presents unique challenges, and implementing targeted strategies ensures optimal deployment performance. For instance, Prompt Engineering Techniques help stabilize Generative AI models, while Checkpointing and Batch Processing improve Deep Learning model performance. Integrating Feature Stores enhances data consistency in Traditional ML models, and employing Blue-Green Deployment ensures seamless updates for Reinforcement Learning models.
To achieve success, organizations can leverage AI Observability tools like Prometheus, Grafana, and OpenTelemetry to proactively detect performance degradation. Implementing intelligent rollback strategies helps maintain uptime and reduces deployment risks. Ensuring Holiday Readiness through strategies like load testing, circuit breakers, and caching enhances system resilience.
Additionally, adopting a structured Cloud Migration strategy using hybrid cloud setups, synchronization tools, and secure data encryption strengthens model deployment stability. Finally, continuously improving AI models through retraining pipelines ensures they remain effective in evolving environments.
By combining these best practices with proactive strategies, businesses can confidently manage AI deployment lifecycles with stability and efficiency.
Resources
- AI Model Lifecycle Management:MLflow Documentation
- AI Deployment Strategies: Kubernetes Deployment Best Practices
- Cloud Migration for AI: Azure Migrate Guide
- AI Observability Tools: Prometheus, Grafana
- Kubernetes Rollback Examples: GitHub Repository
- MLflow Model Tracking & Rollback Automation: GitHub Repository
- Cloud Migration YAML Configurations: GitHub Repository
- Observability Best Practices: Prometheus Documentation
- GPU Node Pool Scaling: Google Cloud GPU Node Pools
- NVIDIA Triton Inference Server for Efficient Inference: NVIDIA Triton Documentation
- AWS DataSync – Automated Data Movement: AWS DataSync Documentation
- Azure Data Factory – Batch Data Migration: Azure Data Factory Documentation
- Anthos – Google Cloud Hybrid Management: Anthos Documentation
- Azure Arc – Extending Azure Services to Hybrid Environments: Azure Arc Documentation
- AWS Outposts – Hybrid AWS Solution: AWS Outposts Documentation
- Canary Deployment with Kubernetes (Flagger): Flagger Documentation
- Google Cloud KMS – Managed Encryption Service: Google Cloud KMS Documentation
- Google Cloud TPUs – AI Hardware Acceleration: Google Cloud TPU Documentation
- AWS Inferentia – Cost-Effective Inference Solution: AWS Inferentia Documentation
- Azure NC-Series VMs – High-Performance AI Model Serving: Azure NC-Series Documentation
- Azure Migrate – Step-by-Step Migration Planning: Azure Migrate Documentation
- AWS Application Migration Service – Replication and Failover: AWS Application Migration Service
- Google Cloud Migrate – Data Integrity Migration Tool: Google Cloud Migrate Documentation
By integrating these strategies, businesses can confidently manage AI deployment lifecycles with stability and efficiency.