Relying solely on standard Kubernetes Services for load balancing can lead to suboptimal performance when sering LLMs. That’s because engines like vLLM provide Prefix caching which can speed up the inference. However, you need to make sure request with same prompt prefix go to the same vLLM instance when you have multiple instances serving the same model. That’s why a standard K8s service won’t work:
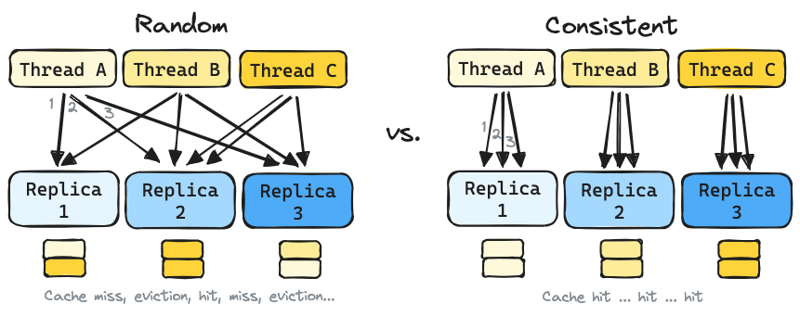
How LLM engines use caching
LLMs use Key-Value (KV) caches to store processed data from input prompts. This “prefix caching” speeds up responses when similar requests are made. However, standard Kubernetes Services distribute requests randomly, causing cache misses and slower responses.
Why Standard Load Balancing Falls Short
Random request distribution leads to:
-
Frequent Cache Evictions: Caches are cleared often, reducing efficiency.
-
Increased Latency: More time is needed to process requests without cache benefits.
A Smarter Approach: Prompt Prefix Consistent Hashing with Bounded Loads (CHWBL)
Prefix/Prompt based CHWBL offers a better solution by:
-
Maximizing Cache Use: Similar requests go to the same LLM replica, keeping caches relevant.
-
Balancing Load: Ensures no single replica is overwhelmed, maintaining performance.
Real-World Benefits
Implementing CHWBL has shown:
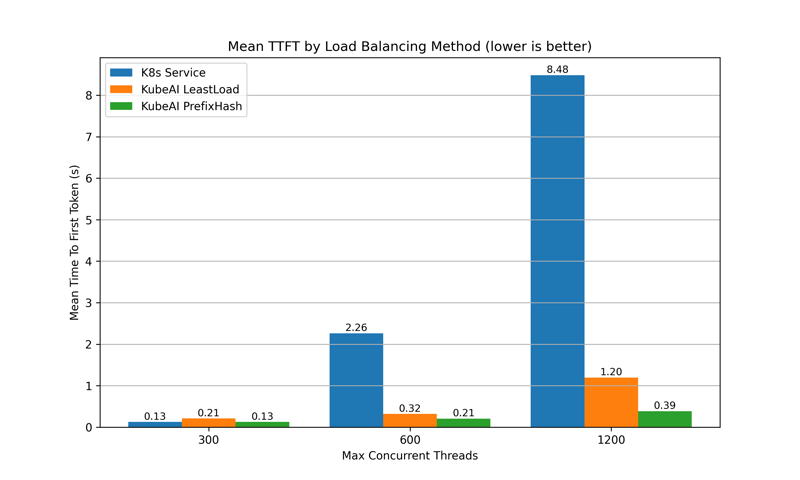
-
95% Faster Initial Responses: Quicker start to data processing.
-
127% Increase in Throughput: More requests handled efficiently.
Conclusion
For effective LLM serving, move beyond standard Kubernetes Services. Adopting advanced load balancing like CHWBL can significantly enhance performance and user satisfaction.
Paper used as the source: Prefix Aware Load Balancing Paper