There has been a lot of discussion around multimodal AI recently — how these systems can be built, open source options, small-scale alternatives, as well as tools for addressing fairness and bias in multimodal AI.
With its ability to simultaneously process different data types (think text, image, audio, video and more), the continuing development of multimodal AI represents the next step that would help to further enhance a wide range of tools — including those for generative AI and autonomous agentic AI.
To that end, improving how machines can find relevant information within this growing range of diverse data types is vital to further improving the capabilities of multimodal AI.
This could mean using a text prompt to search for a specific photo or video (text-image, text-video), or vice versa — a process that many of us are already familiar with.
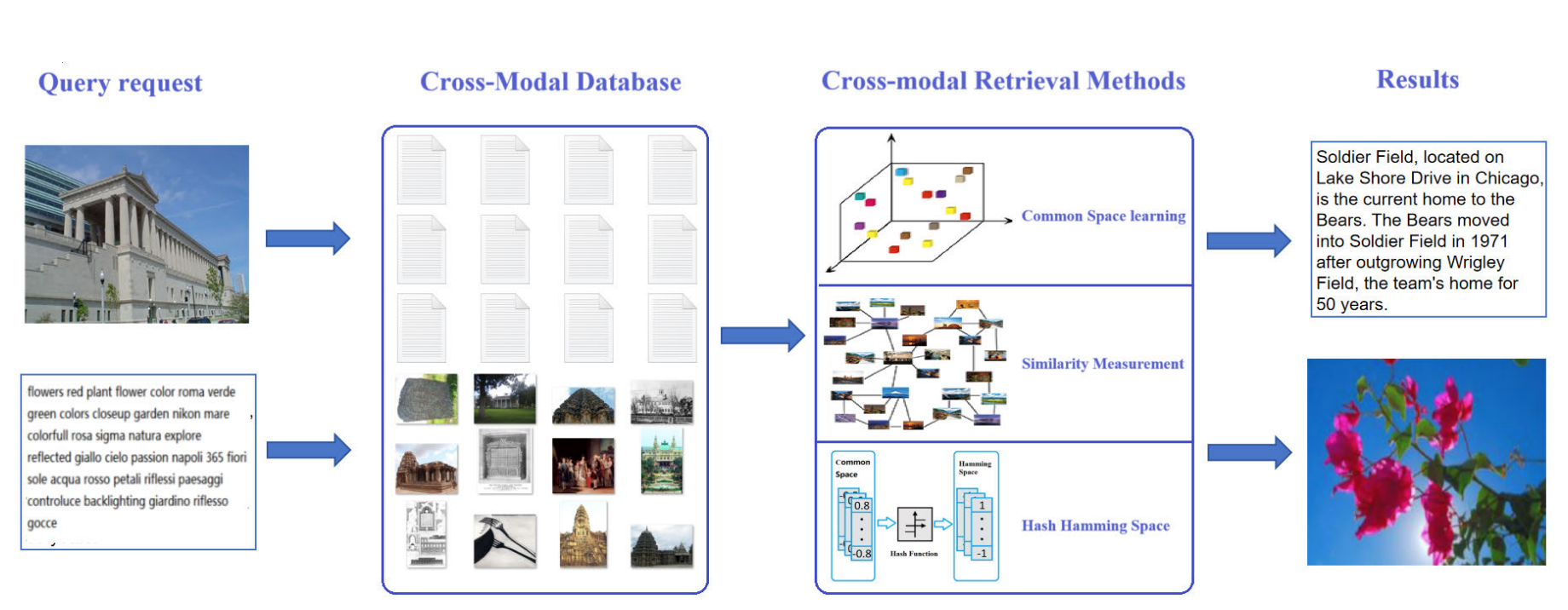
General process of cross-modal retrieval. Via Z. Han et al.
How Cross-Modal Retrieval Works
The goal of cross-modal retrieval is to extract pertinent information across various types of data. However, this can be challenging due to the differences in data structures, feature spaces and how that information might be semantically portrayed across different modalities.
This results in a misalignment between those various semantic spaces and difficulties for direct comparison — a problem that researchers call the heterogeneous modality gap. Consequently, much of the research in the cross-modal retrieval field centers around finding and establishing shared frameworks for multimodal data, in order to facilitate cross-modal retrieval tasks.
Representation Learning in Cross-Modal Retrieval
To tackle this problem, most cross-modal retrieval methods will typically use what is called representation learning. This process simplifies various kinds of raw, modal data into patterns — or representations — that a machine can understand so that they can be mapped into a shared space or framework, thus facilitating the extraction of useful information. Representation learning helps to enhance interpretability, uncover hidden features and also makes transfer learning easier.
Generally, these representation learning approaches in cross-modal retrieval can be split into two types: real-value retrieval and binary-value retrieval, as well as supervised and unsupervised forms of each retrieval type.
Real-Value Retrieval
Real-value-based cross-modal retrieval aims to distill low-dimensional, real-value features of multimodal data, thus retaining more in-depth semantic information.
A common representation space can be shared between different data types, with the most correlated data sitting adjacent to each other within that space.
For many years, one of the most commonly used algorithms for cross-modal retrieval was canonical correlation analysis (CCA), a classical statistical method that extracts features from the raw data, and then maximizes the correlation between paired representations of cross-modal data — such as images and text — before aligning them in a common subspace in order to facilitate cross-modal retrieval. However, the drawbacks to CCA include significant semantic gaps between different modalities, as it’s best used for capturing statistic relationships, rather than more complex, nonlinear semantic relationships.
While real-value representation learning methods allow different data modalities to be more directly measured, the downside is that this approach requires more storage and computational resources.
Though classifications of real-value retrieval methods vary, they fall into these general categories, which can either be supervised or unsupervised:
- Shallow real-value retrieval: Uses statistical analysis techniques to model multimodal data associations.
- Deep real-value retrieval: Involves the learning of features, joint representations, complex semantic relationships and patterns across varying data types, using deep neural networks.
- RNN (recurrent neural network) models: Used primarily to process sequential and time series data (like text, video), and to combine it with image features extracted through CNN (convolutional neural network) models.
- GAN (generative adversarial network): This deep learning architecture uses competing “generator” and “discriminator” components in order to learn the distribution of data. When used in cross-modal retrieval, it enables the model to learn correlations across varying data types.
- Graph regularization: Due to its ability to accommodate multiple modalities within an integrated framework, it can capture a wide range of correlations between different forms of data.
- Transformer methods: Based on an innovative self-attention mechanism, the transformer architecture allows deep learning networks to concurrently process all incoming inputs, making it an effective option for cross-modal retrieval tasks.
Binary-Value (Hashing) Retrieval
Also called hashing-based cross-modal retrieval, this form of representation learning encodes data from different modalities by compressing them into binary code, which is then transposed into a common Hamming binary space for learning, thus enabling more efficient and scalable search, and reduced storage needs, though accuracy and semantic information may be slightly reduced. Yet another advantage of hashing retrieval is that binary hash codes are shorter and more simplified than the original data, which helps to alleviate what computer scientists call the curse of dimensionality.
In both supervised and unsupervised hashing, hash functions are learned via an optimization process that minimizes the discrepancies between the original data and binary codes.
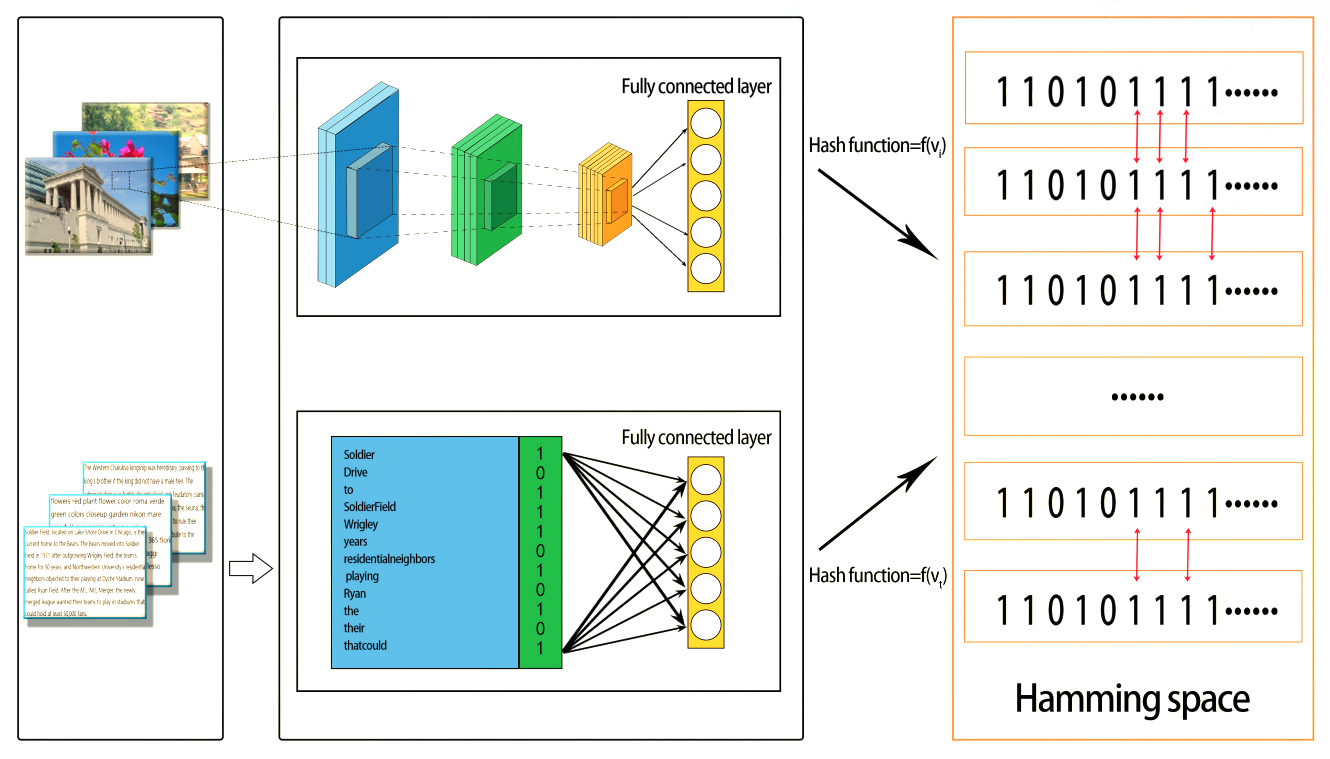
General framework of cross-modal hashing retrieval. Via Z. Han et al.
Cross-modal hashing techniques can be divided into three main categories:
- Supervised: Uses labeled data to train the hash functions, which helps to preserve the semantic similarities between paired instances of multimodal data while also maximizing the Hamming distance between non-matched instances. Supervised cross-modal hashing can be further classified as either shallow or deep learning-based.
- Unsupervised: Does not use labeled data and instead relies on learning, has functions solely from data distribution. These techniques utilize the correlation between data modalities to learn the relationships between them as encoded in binary form. Similarly, unsupervised methods can also be subdivided into shallow and deep retrieval methods.
- Semi-supervised: These methods will leverage rich, unlabeled datasets to improve the performance of models’ supervised learning.
Why Cross-Modal Retrieval Matters
As information becomes increasingly multimodal and heterogeneous, it will become vital to address the challenges in the field of cross-modal retrieval. This will help to close the gap between different data forms, boosting the accuracy and relevance of search results for human users, while also allowing machines to understand the world in a more human-like way.
When applied in the real world, cross-modal retrieval can be leveraged for a wide range of use cases, like automatically generating accurate descriptions of various types of content. This enhances voice assistants’ capabilities to understand complex queries, or helps to establish more natural and intuitive human-computer interactions.
As cross-modal retrieval continues to evolve, issues like the heterogeneous modality gap, improving hierarchical semantic alignment and nonlinear correlation learning between different modalities will require more development, as well as enhancing user interfaces, privacy and security.
Cross-Modal Retrieval Tools
To dig deeper into the available research into cross-modal retrieval and a dizzying array of tools and datasets, you can check out this categorized list on GitHub, as well as this toolbox, which includes some open source repositories.
The post Cross-Modal Retrieval: Why It Matters for Multimodal AI appeared first on The New Stack.