
Thanks to its performance and adaptability, Open Policy Agent (OPA) is a common choice for managing policy-as-code. Nonetheless, security flaws can develop if OPA is abused or improperly designed, much as with any tool handling important tasks like authorization and compliance. Recent research, including a vulnerability found by Tenable reveals how attackers may exploit policy code to access sensitive data or compromise infrastructure.
This article will go over methods for writing OPA policy-as-code in a secure way. We will focus on how certain anti-patterns in policy codes could be exploited and how real-world experiences—such as large-scale OPA deployments like Permit.io—can highlight best the approaches to dealing with these vulnerabilities.
We also will see how the open-source OPAL (Open Policy Administration Layer) project can ensure your OPA instances are safe and up-to-date with the relevant policies and data.
Vulnerabilities in OPA and their Root Causes
Tenable uncovered a vulnerability that exposed one of the more notable instances of policy engine abuse. In certain scenarios, attackers could craft malicious Rego policies that executed functions not originally intended for policy enforcement — such as making external network calls or accessing environment variables. This opened the door to data exfiltration and credential leaks such as:
- Remote Calls Within Policy: Attackers using built-in functions like http.send or net.lookup_ip_addr to leak environment variables or credentials (including cloud metadata keys).
- Windows UNC Path Exploits: A scenario where an OPA CLI or SDK function could be tricked into loading a bundle over a remote share, leading to forced SMB authentication and exposure of NTLM credentials.
These vulnerabilities share a central theme: anti-patterns in policy code and deployment practices. Although Rego is a domain-specific language intended for policy decisions, developers sometimes use it as a general-purpose scripting tool. When sensitive built-ins aren’t restricted, or if policy code can pull data from untrusted sources, the risk of exploitation increases significantly.
Security issues typically arise when Rego policies exceed their intended scope, becoming gateways for unintended functionality or network access. Understanding these pitfalls is the first step toward enforcing strict guardrails and preventing attackers from misusing your policy engine.
Expertise with OPA and Rego at Scale
Permit utilizes OPA as its core engine for fine-grained authorization, managing and authorizing millions of requests each day. Central to Permit’s approach is their use of OPAL (Open Policy Administration Layer), an open-source tool designed to enhance developers’ use of OPA. OPAL facilitates real-time policy updates and ensures that authorization data remains consistent across all OPA instances.
With extensive experience in deploying Rego and OPA at scale, the Permit team was able to compile a set of best practices that address common challenges and security concerns. The following sections outline these best to ensure secure and efficient policy-as-code implementations with OPA.
Best Practices for Secure OPA Deployment
Securing policy-as-code with OPA involves more than just writing effective policies. It requires a comprehensive approach to policy development, management, and deployment. Here are their best practices for maintaining a secure OPA implementation:
1. Separate Policy Code from Application Code
Maintaining a clear separation between policy logic and application functionality is crucial for ensuring the security and maintainability of your policy-as-code setup.
Rego, OPA’s policy language, is designed to make policy decisions based on input data. When developers embed additional functionality, such as data retrieval or external calls, into Rego policies, they not only complicate them but also open up potential security vulnerabilities.
Incorporating functions like http.send can, for example, inadvertently allow policies to exfiltrate sensitive data if not properly restricted.
It’s important that you focus on keeping your Rego policies strictly for evaluating conditions and making access decisions. Any data fetching or processing should be handled outside of the policy engine, ensuring policies remain simple and secure. This means your policies should be dedicated solely to evaluating conditions based on the provided data without embedding any data retrieval or processing logic within the policies themselves.
Utilizing OPA’s built-in testing framework and static analysis tools can help enforce this separation. For example, you can create tests that verify no disallowed built-ins (like http.send or net.lookup_ip_addr) are present in your policies:

Adhering to this practice minimizes the attack surface of your policy engine. Policies remain focused and predictable, making them easier to review and audit and preventing malicious actors from exploiting embedded functionalities to compromise your system.
2. Decouple Schema and Data
Maintaining a clear separation between policy logic and dynamic data is also a critical part of creating secure Rego policies. By decoupling schema from data, you can ensure your policies focus on decision-making and aren’t cluttered with data definitions. This significantly reduces the risk of unintended behaviors and simplifies their management.
Make sure your policies evaluate inputs based on external data sources, and keep their logic clean and straightforward.
If we take a look at a scenario where user roles and permissions are managed externally rather than being hard-coded within the policies, it’s easy to see how policies remain generic and adaptable to changes in user roles without requiring modifications to the policy code itself.

In this example, the policy checks the user’s role against an external data source (data.roles) rather than defining the roles within the policy itself. Any updates to user roles are managed through the data layer, while policies remain unchanged – reducing the risk of introducing errors during updates.
How to Implement This:
- External Data Sources:
- Store user roles, resource definitions, and other operational data in external data stores such as databases, APIs, or configuration files.
- Ensure that this data is regularly updated and synchronized with your policy engine using tools like OPAL.
- Policy Administration Layer:
- Utilize OPAL to manage and push both policy and data updates to OPA instances. OPAL ensures that policies and their corresponding data remain in sync, maintaining the integrity of access decisions.

3. Structured Data Management:
- Organize your data sources in a structured manner, categorizing data based on its purpose and usage within policies. This organization facilitates easier management and updates.

4. Minimal Context Passing:
- When evaluating policies, pass only the necessary context to OPA. Avoid including extensive or sensitive data within the input, relying instead on external data sources to provide the required information.

Decoupling schema and data thus offers several advantages: It enhances security by preventing policies from being manipulated through data injections or unauthorized access. Policy management becomes simpler as policies remain focused on decision-making without being cluttered by data definitions. Flexibility and scalability are improved, allowing user roles and resource definitions to be updated independently of policy code. Finally, this also has a great effect on auditing and compliance, as the clear separation enables independent reviews of policies and data sources.
3. Secure the Agent Itself
Managing how your OPA receives data is another important part of maintaining a secure environment. Traditionally, OPA can be configured to pull data from external sources, but this pull-based approach can introduce security risks. If OPA is allowed to fetch data autonomously, it might inadvertently retrieve malicious or unintended information, potentially compromising your authorization framework.
To address this, Permit adopts a push-based strategy using OPAL (Open Policy Administration Layer). OPAL acts as an administration layer that detects changes in policies and data sources in real time and pushes these updates directly to all OPA instances. This method ensures that only verified and necessary data is introduced into your policy engine, significantly reducing the risk of unauthorized access or data exfiltration.
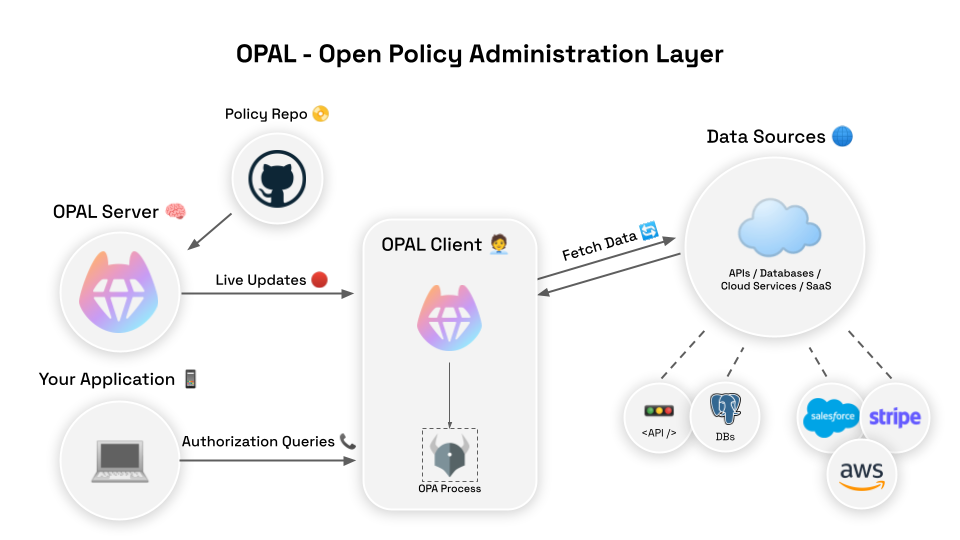
OPAL’s event-driven architecture that pushes the data to OPA via OPAL clients
OPA allows you to define its capabilities through a configuration file, where you can specify which built-in functions are permitted and restrict external communications. By configuring capabilities in OPA’s config.yaml, you can control which domains OPA is allowed to communicate with and disable potentially dangerous functions:

This is an example of just one configuration that ensures OPA can only send requests to trusted domains and prevents using functions that could be exploited to leak sensitive data. When starting the OPA agent, you load this configuration to enforce these restrictions:
opa run –server –config-file config.yaml
Thus, the permit team uses OPAL to efficiently manage policy and data updates across thousands of OPA instances, ensuring all policy engines are consistently and securely updated without the need for manual intervention.
4. Store Policy Code Securely Through GitOps
Managing and storing your Rego policy code in a secure and organized manner is another fundamental part of your policy-as-code setup. Relying on ad-hoc storage solutions, such as direct uploads to S3 buckets, can expose your policies to unauthorized access and accidental misconfigurations. Instead, adopting a GitOps approach ensures that your policies are version-controlled, auditable, and consistently deployed across all environments.
This is another thing OPAL can help with by allowing you to integrate Git-based repositories into your policy management workflow. Permit uses OPAL to ensure all Rego policies are stored in Git repositories, enabling version control and collaborative reviews. OPAL monitors these repositories for any changes and automatically pushes updates to all connected OPA instances. This GitOps mechanism enforces a disciplined approach to policy management, where every change is tracked, reviewed, and tested before being applied.
Consider a scenario where a new policy needs to be deployed. A developer makes changes to the Rego files in the Git repository and submits a pull request. OPAL would thus detect the approved changes and push the updated policies to all OPA instances, ensuring that the new rules are uniformly applied without manual intervention. This minimizes the risk of human error and ensures that all policy engines are always in sync.
5. Incorporate CI/CD and Branching Mechanisms
Integrating Continuous Integration and Continuous Deployment (CI/CD) pipelines with your policy-as-code workflow is another must for maintaining consistency, reliability, and security in your policy deployment. The combination of CI/CD best practices alongside effective branching strategies ensures that all policy changes are thoroughly tested and reviewed before reaching production.
This integration allows for automated testing, validation, and deployment of Rego policies, ensuring that only verified and approved changes are applied across all OPA instances.
When a developer commits a new policy rule to the Git repository, you can, once again, use OPAL to detect the change and trigger the CI pipeline to run unit tests and static analysis checks. Only after passing these tests are the changes automatically deployed to all relevant OPA instances.
By incorporating CI/CD pipelines and branching mechanisms, you can ensure that policy changes are deployed uniformly and securely, reducing the risk of introducing vulnerabilities or misconfigurations.
Example Workflow
“`
# Example GitHub Actions workflow for OPA policies
name: CI Pipeline

A well-structured policy deployment pipeline includes automated testing, a branching strategy, and automated deployments. Whenever changes are pushed to development or staging branches, the pipeline runs unit tests and static analysis on Rego policies to ensure they meet required standards before merging into production. Following a GitFlow model, policy changes are first made in feature branches, tested in development and staging, and only merged into production after passing all checks. OPAL can be used in this context to monitor the production branch and automatically deploy approved policies to all connected OPA instances, ensuring consistency across deployments.
6. Employ Design Patterns in Policy as Code
Adopting consistent design patterns when writing Rego policies enhances the readability and maintainability of your policy-as-code framework. Design patterns provide a structured approach to organizing your policies, making it easier to manage complex authorization logic and reducing the likelihood of errors or inconsistencies.
Structured policy design ensures policies are effective, easy to understand, and auditable. By following established design patterns, you can create clear and predictable policy rules that align with your organization’s security requirements.
Ensuring that each policy rule has a single, clear source of truth prevents duplication and confusion. Instead of scattering similar rules across multiple files, you can organize them into dedicated modules based on functionality or domain.
“`
# Example of a well-structured Rego policy module

Additionally, leveraging Rego’s capabilities to create reusable rules and utilizing inheritance where appropriate can significantly reduce redundancy. By centralizing common logic, such as role definitions or permission checks, you streamline policy updates and ensure consistency across your authorization framework.

Design patterns offer several key benefits, including enhanced readability, improved maintainability, reduced complexity, and easier auditing. A consistent structure and naming conventions make policies more readable, enabling better collaboration and faster onboarding of new team members. Modular and organized policies simplify updates while minimizing the risk of errors when modifying or adding new rules, and clear separation of concerns and reusable components help manage complexity, ensuring that each policy serves a distinct purpose without unnecessary overlap. Well-structured policies facilitate auditing and compliance reviews, making security assessments more effective.
7. Use Well-Defined Permission Models
Lastly, establishing a clear and structured permission model is key for secure policies. By aligning your Rego policies with established frameworks like Role-Based Access Control (RBAC) or Attribute-Based Access Control (ABAC), you ensure that your authorization logic is both scalable and maintainable.
Integrating well-defined permission models into your policy-as-code practices simplifies the management of access controls and enhances the clarity and enforceability of your policies.

In this example, only users with the “admin” role are granted all permissions, while users with the “viewer” role are limited to read-only actions. The clear separation of roles and permissions RBAC provides helps prevent unauthorized access and simplifies policy maintenance.
Alternatively, ABAC allows for more granular control by evaluating attributes associated with users, resources, and the environment. This model is particularly useful in dynamic environments where access decisions need to consider multiple factors.

Here, access is granted based on the user’s department, the type of resource, and the specific action they intend to perform. This level of granularity ensures that policies can adapt to complex and evolving access requirements.
What Next?
As organizations increasingly adopt OPA for managing authorization and compliance, they must also ensure the security of their policy-as-code implementation. The vulnerability discovered by Tenable highlights the critical importance of adhering to best practices to prevent potential exploits and maintain the integrity of your authorization framework.
By following the best practices outlined in this article—from keeping Rego policies focused solely on policy decisions to leveraging OPAL for centralized policy management—you can significantly enhance the security and reliability of your OPA deployments. These practices help mitigate risks associated with misconfigurations and insecure coding patterns, ensuring that your policy-as-code environment remains robust against evolving threats.
For developers seeking to implement these best practices effectively, Permit.io offers comprehensive solutions that simplify the deployment and management of OPA and Rego policies at scale. These tools are there for you to leverage and build a secure, scalable, and maintainable authorization system tailored to your specific needs.