With observability data growing at a breathtaking rate, San Francisco-based startup Sawmills believes a new category is emerging to manage the volume of data and make it more useful.
“Teams are drowning in telemetry data and burning through budgets, yet still struggling to get real insights. We built Sawmills to fix this — intelligent telemetry management that filters, enriches and routes data before it hits your observability stack,” co-founder and chief product officer Erez Rusovsky wrote in a LinkedIn post.
The company stresses that it is not an observability vendor but sits between data ingestion and the observability offering. It uses AI on top of OpenTelemetry Collector, an observability pipeline middleware that can receive, process and export data at scale, then adds capabilities to eliminate useless or duplicate data, set guardrails on the amount of data sent to the vendor of choice, and recommend ways to use telemetry data more effectively.

Sawmills co-founders Amir Jakoby, Ronit Belson and Erez Rusovsky
“A big point that convinced us that we want to get into this … is the understanding that the new technology, AI, etc., creates a new opportunity to solve the problem in a way that we believe our target audience really wants. DevOps doesn’t want another tool that they need to configure, so the ability to do it in a smart way is a big part of the solution,” said Sawmills CEO Ronit Belson.
Way, Way Too Much Data
Microservices architectures in particular are generating an explosion of data, yet observability vendors charge by the amount of data ingested, leading to whopping bills — such as $65 million to Datadog for one unsuspecting customer.
Log data grew 250% year-over-year on average, respondents to a 2024 Chronosphere survey reported, and 22% said they create 1 terabyte or more of logs each day. Add in the data for events, traces and other metrics, and the volume becomes clearly unsustainable. Yet those survey respondents maintained that they’re struggling to gain useful insights from that data.
While storing all the data has historically been the way to go, lest something goes wrong down the road and it’s needed to pinpoint the cause, even with cost-efficient storage, the volume of data has made that infeasible.
“So many engineering teams these days have polyglot storage and microservices where different components are written in different languages and different frameworks. It’s increasingly harder for a magical approach to cover the breadth that we see in modern infrastructure,” Honeycomb co-founder and CEO Christine Yen explained in a recent episode of The New Stack Makers.
Larger organizations, then, are turning to telemetry pipelines that aggregate and process data from multiple sources, according to a Gartner report, which advises focusing on the value and return on investment in such a strategy.
Addressing the Pain of Massive Data Volumes
The Sawmill co-founders — Belson, Rusovsky and Amir Jakoby, all with deep experience in DevOps — originally set out to build a startup based on instrumentation. But in conversations with prospective companies, they were told that the volume of data was the biggest problem. They were shocked to be told that only about 10 percent of that data is useful. And data quality, such as missing data points, inconsistent formats and duplicate data, is a pain point as well.
“A lot of the data is duplicate data. Think about an error message that repeats 10 million times. Do you need 10 million messages? Probably not. You probably need one message to say, ‘Oh, this message repeated 10 million in times,’ right?” Rusovsky said.
When you send a lot of data you don’t need, it also hurts the effectiveness of the observability solution, Belson explained
“Doing root cause analysis with a lot of data that is not of good quality is really harder. So there are bunch there are a bunch of problems that are the outcome of the amount of data that is sent, and data that you don’t necessarily need,” Belson said.
OpenTelemetry Collector is “the engine that allows us to manipulate the data in stream, and we’ve built a management layer above it, and the insight and smartness layer above that,” Rusovsky said.
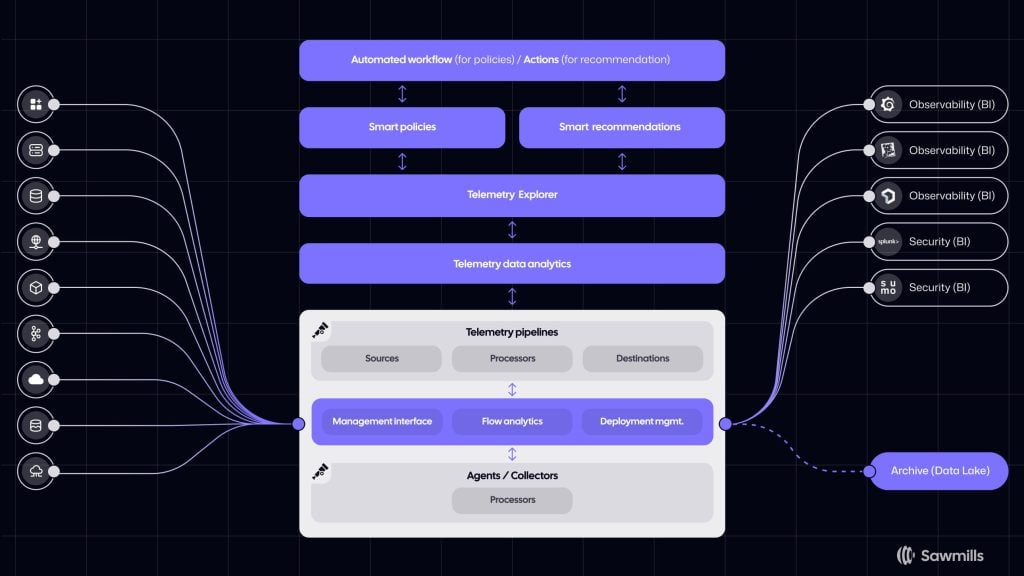
The company works with clients to install agents on their own telemetry pipelines that send data to Datadog, New Relic, Elastic or wherever. The agents process the data using AI models through the SaaS offering, which automatically identifies opportunities to reduce spending and improve data quality, but Sawmills has no access to the data, Jakoby pointed out. The customer has full control of where it resides and decides which data to send.
“The customer doesn’t need to pay egress and we don’t need to process the data, spending on CPU, etc. … so there’s no extra cost for anything that goes to waste,” Jakoby said.
AI and machine learning are used in both the streaming data and the recommendation engine. The engine uses proprietary tools such as OpenAI or AWS Bedrock, but also customers’ own cloud-based large language models. While AI/ML can identify patterns, some data is specific to apps the company has developed, so the customer decides which data is relevant.
Customers can set up guardrails on the amount of data to be sent, receiving alerts when they’re nearing those limits. They also can apply Sawmills’ recommendations with a single click and set automated policies to prevent unexpected overages and availability issues. The architecture also allows customers the flexibility to seamlessly switch observability vendors.
When alerted about nearing one of its limits, there are a number of things that can be done, according to Rusovsky: sampling, aggregating or just sending data to low-cost storage and notifying the team to decide what to do with it.
“I think there is a growing understanding that the customers want to own that data,” Belson said. “They don’t want the observability solution to own that data.”
Seizing the Opportunity
The 10-person company is around a year old. CEO Belson previously was chief operating officer at Testim.io (acquired by Tricentis), Rollout.io (acquired by CloudBees) and Cloudmeter (acquired by Splunk). CTO Jakoby previously was vice president of software engineering at New Relic, director of engineering at SignifAI, lead security engineer at Preempt Security and software engineering manager at Israeli Military Intelligence Unit 8200. Rusovsky was product director at CloudBees and CEO and co-founder of Rollout.io.
With $10 million in seed funding just raised, the company expects to double headcount in the next six months, Belson said.
It faces competition from startups such as SigNoz, Kloudfuse and Edge Delta as well as Cribl.io, not to mention that major vendors such as Datadog, New Relic, Elastic and Splunk are doubling down on OpenTelemetry Collector data as well.
“There’s no way for all that data to go unmanaged like this,” Rusovsky said. “There are too many problems associated with this, so we have a strong conviction that there is a category that is being formed now managing that data, and we hope to seize the opportunity on that side.”
Liran Grinberg, managing partner at Team8, which led the recent seed round, called telemetry data management a fast-emerging, critical new category.
“Addressing cost is important, but the real challenge is governance, flexibility and the ability to derive actionable insights from the data being collected. Sawmills is tackling this challenge head-on,” he said in a blog post. “The Sawmills team has a deep understanding of the problem and a comprehensive vision that perfectly positions them to own this new category.”
The post Carving Relevance Cost-Effectively From Observability Data appeared first on The New Stack.