
Half of engineers don’t strongly trust the data they rely on the most in their central system of record, according to Port’s “2025 State of Internal Developer Portals” report. This presents a major issue for developers and engineering teams generally because these central systems of record are essential tools for modern software development.
When engineering metadata is inaccurate, it becomes impossible to trust. This means engineers may be less willing to rely on the data they have access to — even if it can be verified — because of prior issues with data, repeated change failures or a general sense of being “burned” by inaccurate stats. Without accurate data, teams become vulnerable to competitors and degradations in the quality of the software produced.
Each central system of record, such as Confluence, a configuration management database (CMDB) or Jira, contains key details about your developers’ effectiveness, your team’s throughput, your system’s stability, your software infrastructure and your teams’ associations with each piece of software by owner. A lack of trust in this data can further cause issues for developers and engineering managers when it comes to making coding decisions, handling incidents, rolling back failed deployments and prioritizing tasks according to business value. If they don’t (or can’t) trust this data, they are often making decisions based on incomplete or inaccurate information.
Problems With Legacy Data Collection Methods
A lack of trustworthy data will exacerbate the issues you face within your software development pipeline and engineering culture. If your team isn’t able to access accurate, real-time or near-real-time metadata about your organization, you’ll struggle to address incidents, improve developer effectiveness and manage costs.
But despite the limitations traditional methods have, many organizations continue to rely on them in some fashion, with 25% of organizations continuing to use a CMDB and 17% continuing to use spreadsheets, according to the report.
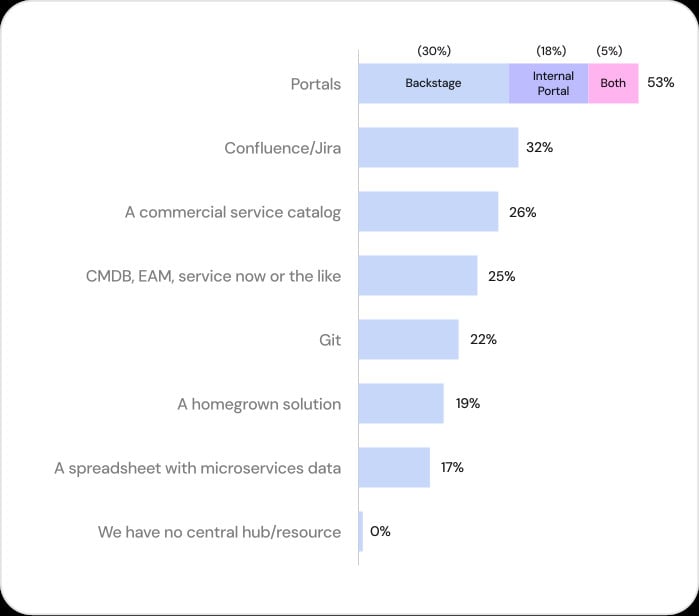
Breakdown of methods teams use to track engineering system metadata. “2025 State of Internal Developer Portals,” Figure 9.
Usually, organizations haven’t shifted to new methods of tracking software asset metadata for one of the following reasons:
- They’ve invested years into configuring and extending them to fit their specific needs.
- They feel resistant to transitioning to modern alternatives, which can disrupt workflows.
- If there are significant workflow pain points and inefficiencies, adopting a new tool could be too high a cognitive load to take on without proven value up front.
These are all common reasons you may hear when trying to adopt new tools or build a new engineering culture. As a result, few organizations have data that is truly up to date. Just 6% of the engineers surveyed reported manually updating software asset metadata into systems like spreadsheets, Confluence, Jira or a CMDB on a daily basis — and 53% of organizations do not update their metadata repositories more than once per week.
Moreover, most common metadata repositories offer limited interoperability with complementary systems, which leads to difficulties in gathering a full picture of the pipeline. To fill in the gaps, engineers end up using multiple repositories, which opens the door to further inaccuracies and stale information.
Particularly as generative AI (GenAI) continues to impact software development, these tools also cannot typically measure the true impact of your investment into such tools without significant integration work or gathering data manually across multiple engineering systems.
Closing the Gaps Between Developer and Manager
There’s a discrepancy between developers’ trust in these repositories and their managers’ trust in them. While 56% of engineering managers trust the data they can access in their legacy metadata repositories, just 46% of developers do.
Though it’s possible that managers’ higher trust in these repositories comes from less intimate knowledge with their systems, this gap in trustworthiness indicates that engineers and managers may be working from very different positions of understanding. This can contribute to disconnects and further misunderstandings about project goals and priorities, discrepancies between each party’s perceived urgency about particular issues, and more.
This gap in trustworthiness indicates that engineers and managers may be working from very different positions of understanding.
For example, an engineering manager for a specific team may want to understand how that team’s change failure rate has changed quarter over quarter. If they see it has increased, by using just one or two systems to investigate the cause, they may draw the conclusion that failures have increased for negative reasons, such as teams not writing code to spec or experiencing difficulties and rushing to deploy on time.
But when developers investigate, they may use different systems to locate this data and gather different results, such as a period of increased or unexpected false-positive alerts triggering during deployment that caused subsequent deployments to fail. From their perspective, this issue may have been caused by a temporarily faulty environment that was resolved, which means the spike in change failure rate is no cause for future concern.
Meanwhile, developers and engineers have likely already attended countless meetings to discuss the data, agree on its accuracy, present it to management, and propose and implement solutions, taking time away from development and causing everyone frustration.
Scenarios like these indicate not only why accurate information is necessary for modern software development, but also why it is important that everyone in an engineering organization understands and has access to a single, unified, comprehensive metadata repository.
Why Are Internal Developer Portals Gaining Popularity?
According to the “2025 State of Internal Developer Portals,” engineering teams want to move away from these breakdowns in communication and data gathering. Over half (53%) of organizations surveyed have implemented an internal developer portal to address these issues with data accuracy and clarity, and 23% have already implemented an internal developer portal specifically to serve as this metadata repository.
Portals offer a wide view into the development pipeline and ingrained role-based access control (RBAC) that gives anyone in the organization access to data and real-time update capabilities. They reduce the need for additional documentation, but also enable teams to work together from the same starting point on all issues, uniting teams against problems rather than each other.
Portals also offer scalability and greatly reduce the amount of routine manual maintenance previously required to unite all the systems you use throughout your software development pipeline into a single interface. This means developers can spend more time coding, rather than manually checking each external service, comparing the current and old data for updates and then updating the system of record for each change they make.
For more insight, download the full “State of the Internal Developer Portals” report. Check out these case studies if you’re eager to learn more about organizations that are benefitting from a portal. Join the conversation around platform engineering and portals in the Port Community.
The post 50% of Engineers Lack Trust in the Data They Rely on Most appeared first on The New Stack.
Comments are closed.